*Texto originalmente produzido para o XV ENECULT – Encontro de Estudos Multidisciplinares em Cultura, submetido e não aprovado para o GT de Culturas e Identidades.
Pedro Meirelles(1)
Nas últimas décadas, diversas produções acadêmicas têm se dedicado a compreender como a cultura nordestina tem sido (re)produzida em/para produtos culturais e midiáticos que (re)constroem os sentidos em torno do que significa Nordeste e ser nordestino. Esses trabalhos surgem como esforço coletivo para pensar sobre uma identidade conjugada na esfera cultural da sociedade brasileira que se formou de maneira muito específica, constantemente no lugar de oposição – não necessariamente de forma combativa, mas geralmente enquanto posição de alteridade.
Este artigo surge no contexto do projeto de pesquisa de mestrado desenvolvido pelo autor no Programa de Pós-Graduação em Cultura e Territorialidades da Universidade Federal Fluminense, em que investiga as diferentes narrativas e produções de sentido criadas (e disputadas) em torno do Nordeste e dos nordestinos na internet. A partir do levantamento bibliográfico necessário para a pesquisa, percebeu-se a possibilidade de analisar de modo mais criterioso quais são os estudos desenvolvidos em âmbito científico, com recorte específico das Ciências Sociais e Humanas, sobre questões culturais das categorias simbólicas supracitadas.
O objetivo, portanto, é identificar as principais discussões referentes às noções teóricas de identidade e representação quanto ao Nordeste e aos nordestinos nas produções acadêmicas. Para responder a essa pergunta de pesquisa, foi feito um extenso levantamento de artigos, monografias, dissertações e teses cujo foco do trabalho se sustentava sob esses pilares fundamentais. Através de um processo de classificação e categorização sistemática das produções levantadas, além de um reforço técnico de análise textual e semântica (a ser apresentado e detalhado na metodologia), pretende-se descobrir as principais temáticas, enquadramentos e referenciais teóricos.
É importante ressaltar que, embora o artigo tenha uma proposta semelhante e até procedimentos metodológicos similares às pesquisas denominadas “estado da arte”(2) , não é a intenção do autor que esse seja interpretado de tal forma. A proposta aqui é de trabalhar o levantamento bibliográfico das pesquisas produzidas de modo exploratório, sem intenção alguma de se afirmar enquanto mapeamento totalizante. Ou seja, interessa-nos explorar o objetivo de pesquisa modo mais criativo e menos sistemático, a partir de diferentes técnicas de análise que podem oferecer insumos interessantes sobre os debates teóricos em relação principalmente às abordagens conceituais.
Antes de apresentarmos com mais detalhamento a metodologia e as questões de pesquisa, cabe introduzir uma discussão inicial sobre por que as questões sobre identidade e representação são relevantes para o projeto como um todo e, mais especificamente, como dialogam com a pauta nordestina. Na próxima seção, portanto, situamos o debate acerca da centralidade da cultura a partir principalmente da argumentação de Stuart Hall (1997; 2015; 2016), discutindo esse fenômeno sob a perspectiva dos processos indissociáveis de representação e identidade; e, por fim, identificando brevemente como a questão nordestina se encaixa nesse debate.
Identidade, representação e o circuito da cultura
Em mapeamento exploratório sobre estudos da cultura no Brasil, Pitombo et al. (2015), a partir de corpus específico dos trabalhos publicados no Encontro de Estudos Multidisciplinares em Cultura – ENECULT, identifica o eixo temático “Narrativas e representações culturais” como um dos mais populares do evento. A categoria diz respeito a trabalhos que envolvem “a representação e as narrativas acerca da identidade cultural a partir da análise de produtos culturais (…) como programas de TV, músicas, obras literárias, filmes” (p. 12). Embora as autoras não explorem os motivos por trás desse resultado específico, toda a argumentação teórica do texto parte de um mesmo ponto de partida: o interesse crescente de pesquisadores de diferentes campos e áreas para com a centralidade da cultura.
Nesse contexto, o protagonismo da cultura parte de uma perspectiva epistemológica, “em relação às questões de conhecimento e conceitualização, em como a ‘cultura’ é usada para transformar nossa compreensão, explicação e modelos teóricos do mundo” (HALL, 1997, p. 16). Ainda que a cultura em seu sentido mais amplo e dentro do senso comum (produção de hábitos, valores, costumes, normas, tradições, etc. de determinados grupos sociais) tenha um repertório bem antigo, Hall (1997) sinaliza que é no século XX que ela se torna uma problemática para o homem ocidental, quando, principalmente por volta da década de 1950 e 1960, acontece uma espécie de “revolução cultural” que a materializa e a torna substancial tanto na esfera da sociedade(3) civil quanto especificamente para as Ciências Sociais.
A “virada cultural” está intimamente ligada a esta nova atitude em relação à linguagem, pois a cultura não é nada mais do que a soma de diferentes sistemas de classificação e diferentes formações discursivas aos quais a língua recorre a fim de dar significado às coisas. O próprio termo “discurso” refere-se a uma série de afirmações, em qualquer domínio, que fornece uma linguagem para se poder falar sobre um assunto e uma forma de produzir um tipo particular de conhecimento. O termo refere-se tanto à produção de conhecimento através da linguagem e da representação, quanto ao modo como o conhecimento é institucionalizado, modelando práticas sociais e pondo novas práticas em funcionamento.
(id. Ibid, p. 29)
A “virada cultural” define a cultura “como um processo original e igualmente constitutivo, tão fundamental quanto a base econômica ou material para a configuração de sujeitos sociais e acontecimentos históricos” (HALL, 2016, p. 25-26). Epistemologicamente, portanto, a cultura passa a ser interpretada no contexto de outra virada – que Hall chama de “virada linguística” das Ciências Sociais e dos Estudos Culturais –, na qual “o sentido é visto como algo a ser produzido (grafo do autor) – construído – em vez de simplesmente ‘encontrado’” (p. 25). Esse sentido é fruto do que DuGay et al. (1997 apud WOODWARD, 2014) denominaram de “circuito da cultura”, que atravessa diversas áreas e processos/práticas da vida em sociedade.
O argumento desses autores é que “para se obter uma plena compreensão de um texto ou artefato cultural, é necessário analisar os processos de representação, identidade, produção, consumo e regulação” (WOODWARD, 2014, p. 16). Ainda que todos esses processos se atravessem e se influenciem concomitantemente (como melhor representado pelo esquema visual produzido), aqui nos interessa pensar especificamente identidade e representação devido à proposta do projeto, que trabalha com a ideia de disputas de significados e narrativas. Ou seja, voltamos o olhar para as produções de sentido constituintes do circuito cultural a partir da linguagem(4) como “um dos ‘meios’ privilegiados através do qual o sentido se vê elaborado e perpassado”.
Abordamos a questão da identidade cultural, portanto, a partir da discussão em torno do seu caráter construtivo e descentralizado. Nesse cenário, ela é “fixada” através das construções de sentido nas quais “a cultura é usada para restringir ou manter a identidade dentro do grupo e sobre a diferença entre grupos” (HALL, 2016, p. 21-22). Ou seja, de modo simples, as identidades culturais se estabelecem em torno de “comunidades imaginadas” que supostamente compartilham dos mesmos valores, símbolos e mapas conceituais. No entanto, esses elementos não são inerentes às suas essências, mas construídos – e disputados – em diversas arenas culturais. Sobre o sentido de nacionalidade, Hall (2015, p. 31) explica que
As culturas nacionais são compostas não apenas de instituições culturais, mas também de símbolos e representações. Uma cultura nacional é um discurso — um modo de construir sentidos que influencia e organiza tanto nossas ações quanto a concepção que temos de nós mesmos (…). As culturas nacionais, ao produzir sentidos sobre “a nação”, sentidos com os quais podemos nos identificar, constroem identidades. Esses sentidos estão contidos nas estórias que são contadas sobre a nação, memórias que conectam seu presente com seu passado e imagens que dela são construídas.
A identidade nacional (tomada aqui como exemplo específico, mas correlata à noção mais ampla de identidade), portanto, surge “do diálogo entre os conceitos e definições que são representados para nós pelos discursos de uma cultura e pelo nosso desejo (…) de responder aos apelos feitos por estes significados” (HALL, 1997, p. 26). Ou seja, além da questão que envolve o “fazer parte” de um grupo, há uma segunda instância tão importante quanto que diz respeito aos processos de identificação – e, consequentemente, de construção/representação – de determinados valores simbólicos. O discurso de pertencimento nacional só se legitima através dos sistemas de “significação” que fornece aos indivíduos o mapa mental necessário para se perceber enquanto parte de determinada cultura (Hall, 2016).
Para que possamos pensar e discutir sobre identidade, portanto, temos também que falar sobre outro processo-chave do circuito cultural: a representação. É esta esfera que nos oferece tanto os signos quanto os significados necessários para que possamos nos posicionar, ou seja, “é por meio dos significados produzidos pelas representações que damos sentido à nossa experiência e àquilo que somos” (WOORDWARD, 2014, p. 18). Fica evidente, portanto, como todos esses referenciais teóricos – identidade, representação e cultura – devem ser observados, conforme nossa linha de argumento e filiação, sob uma perspectiva construtivista na qual há uma disputa constante pela produção – e identificação – de sentidos compartilhados.
O argumento que estarei considerando aqui é que, na verdade, as identidades nacionais não são coisas com as quais nós nascemos, mas são formadas e transformadas no interior da representação. Nós só sabemos o que significa ser inglês” devido ao modo como a “inglesidade” (Englishness) veio a ser representada — como um conjunto de significados — pela cultura nacional inglesa. Segue-se que a nação não é apenas uma entidade política mas algo que produz sentidos — um sistema de representação cultural. As pessoas não são apenas cidadãos/ãs legais de uma nação; elas participam da ideia da nação tal como representada em sua cultura nacional.
(HALL, 2015, p. 30)
É sob essa linha de pensamento teórico que vários trabalhos de produção acadêmica (artigos, monografias, dissertações e teses) têm feito um esforço para tentar compreender e discutir a identidade e a representação nordestina no âmbito da cultura nacional. Partindo tanto de pesquisas teóricas quanto de pesquisas empíricas e/ou estudos de caso, essas produções analisam – sob diferentes perspectivas – como o Nordeste “nasceu”, foi e continua sendo narrado na arena discursiva da sociedade brasileira. Ou seja, uma vez que a identidade é uma construção fruto dos processos de representação de uma cultura, esses estudos trazem à tona discussões sobre esse circuito para com as categorias “nordestinos” e “Nordeste”.
O que faz “ser” nordestino? Como se inventou o Nordeste? Como meios de comunicação de massa representaram e representam historicamente os nordestinos e o Nordeste? Como a literatura nacional ajudou na criação de uma imagem regionalista? Como as políticas de gestão federal influenciaram no jogo de articulações para a criação da região? Como a música, principalmente o forró, tornou-se um dos principais narradores da legítima experiência nordestina? Como o cinema nacional e as produções audiovisuais televisivas corroboraram em todo esse processo? Essas são algumas das perguntas que envolvem tanto identidade quanto representação e fazem parte do escopo teórico por trás das produções a serem analisadas.
Questões da pesquisa e metodologia
Tendo em vista a relevância – social e epistemológica – dos trabalhos sobre as narrativas e produções de sentido em torno do Nordeste e dos nordestinos enquanto categorias culturais, estabelecemos como objetivo principal e secundários deste trabalho, respectivamente, as seguintes questões:
- Quais são as discussões e os debates em torno das questões de identidade e representação do Nordeste nas produções acadêmicas?
- Quais são as categorias temáticas gerais (referentes ao objeto de pesquisa) dessas produções? Ex: Cinema, Música, etc.
- Quais são as referências bibliográficas que se apresentam com maior frequência nesses recortes?
O primeiro passo para responder a esses questionamentos foi encontrar um corpus de análise minimamente significativo. Foi realizado, então, um levantamento de produções científicas a partir da plataforma de pesquisa acadêmica do Google(5) . Novamente, como o artigo não tem a ambição de fazer um mapeamento completo referente ao estado da arte da temática aqui abordada, esse processo foi mais exaustivo do que totalizante: foram selecionadas 165 produções acadêmicas(6) encontradas a partir da listagem ranqueada por ordem de relevância (segundo critérios da plataforma) que traziam discussões concomitantes sobre identidade, representação e Nordeste.
O segundo passo necessário, após o levantamento de essas produções, foi criar um aporte analítico capaz de nos fornecer as informações requisitadas referentes a cada uma das perguntas da pesquisa. Criamos, então, uma planilha(7) com as seguintes variáveis a serem preenchidas com os dados de cada produção encontrada: tema/área, título, autor(es/as), resumo, ano, bibliografia e tipo de trabalho. Essa categorização sistemática dos dados levantados permite que possamos começar a delinear as respostas que desejamos fornecer às questões deste trabalho. Na próxima seção, apresentamos como ficou a disposição de corpus e resultados da análise.
Resultados da análise exploratória

FONTE – O autor
Dentre as produções acadêmicas mapeadas, a grande maioria foram do tipo Artigo (70%) – referentes a apresentações em eventos, anais de congressos, projetos científicos, etc.; seguido de Monografia (15%) e Dissertação (11%), com apenas quatro Teses (2%) encontradas. Quanto à época de produção dos trabalhos, há uma concentração relativamente estável sobretudo na última década (de 2009 em diante), com um pico considerável em 2014 – não há nenhuma novidade ou acontecimento explícito nos dados que provoque esse aumento repentino, visto que os trabalhos desse ano específico abordam temas antigos em geral (principalmente Literatura e Música).
É importante ratificar que essas informações não dizem respeito à toda produção acadêmica sobre identidade, representação e Nordeste/nordestinos, mas pode ser vista como indicativo para possíveis futuros mapeamentos mais aprofundados – e, principalmente, delimitam e apresentam o corpus de análise selecionado. É nesse mesmo contexto que apresentamos na Figura 02, na qual foram contabilizadas as Áreas/Temas dos trabalhos (referentes especificamente aos objetos de pesquisa e/ou discussão teórica). Foram identificadas em apenas um trabalho: Turismo, Teatro, Religião, Letras, Biblioteconomia, Política, Direito e Artes.

FONTE – O autor
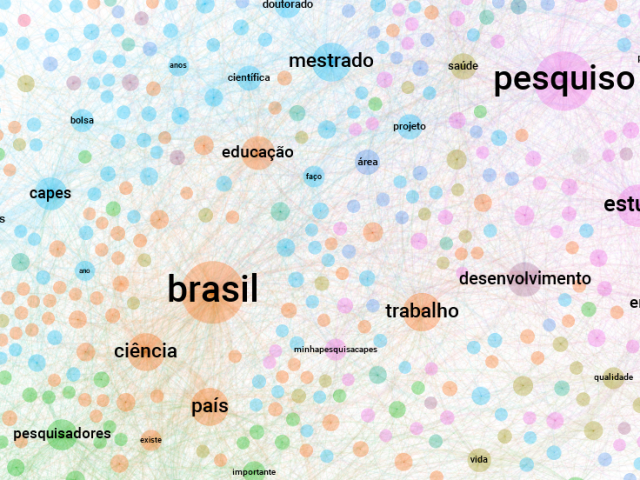
As produções sobre Cinema (20%), Música (20%) e Literatura (19%) somam juntas mais da metade do corpus de análise. São trabalhos que analisam especificamente ou de maneira mais abrangente como as produções culturais – filmes, canções, cantores(as), romances, cordel, etc. – dessas áreas atravessam, influenciam ou envolvem questões relacionadas à (construção da) identidade nordestina e da representação do Nordeste e do povo nordestino. Na Figura 03, três esquemas de nuvens de palavras (mais frequentes) foram produzidos 8 a partir dos títulos dos trabalhos para ilustrar alguns dos assuntos recorrentes em cada uma dessas categorias.

FONTE – O autor
Retomando a Figura 02, temos ainda vários trabalhos que foram classificados na categoria Geral. As produções aqui atribuídas trabalham as questões de identidade, representação e Nordeste sob uma perspectiva mais conceitual e teórica, sem um recorte específico de objeto de estudo e/ou análise. Já Pedagogia e Migração/Territorialidade apontam produções bem específicas, abordando, respectivamente, como o Nordeste é/pode ser visto em sala de aula (ou no processo de ensino e aprendizagem como um todo), e em estudos que discutem sobre a questão da migração nordestina em relação também a uma noção de territorialidade.
As produções sobre Internet são, em sua maioria, estudos de caso sobre páginas da web e/ou de mídias sociais nas quais a identidade nordestina é reconfigurada simbolicamente para o “ciberterritório”. Em Televisão, autores discutem sobre o modo como o Nordeste e os nordestinos são representados/retratados nas narrativas audiovisuais “fictícias”, assim como acontece nos trabalhos categorizados em Imprensa. Por fim, a categoria Gênero surge não necessariamente como uma temática, mas como uma área de pesquisa – que, aqui especificamente, discute principalmente as questões sobre a “masculinidade” nordestina.
Em sequência, interessa-nos também descobrir quais são os autores mais populares que embasam essas discussões. Para isso, foi desenvolvido um código em linguagem de programação R que contabilizou todos os termos em caixa alta (conforme padronização nos modelos da ABNT) das bibliografias mapeadas; em seguida, averiguou-se, a partir da listagem em ordem de maior frequência, quais eram referentes a autores (e excluídos termos como siglas de universidade, nomes de editoras, etc.); para finalizar, a verificação final foi feita com o software AntConc(9) . A listagem dos autores mais citados com o número de ocorrências está disposta a seguir:
| Autores | Frequência Bibliográfica |
| Durval Muniz de Albuquerque | 182 |
| Stuart Hall | 98 |
| Michel Foucault | 62 |
| Tomaz Tadeu da Silva | 47 |
| Zygmunt Bauman | 43 |
| Eni Pucicinelli Orlandi | 39 |
| Mikhail Bakhtin | 39 |
| Gilberto Freyre | 39 |
| Néstor García Canclini | 36 |
| Alfredo Bosi | 33 |
| Pierre Bourdieu | 31 |
| Luís da Câmara Cascudo | 31 |
| Renato Ortiz | 30 |
| Homi K. Bhabha | 25 |
| Michel Pêcheux | 24 |
| Antônio Cândido | 24 |
| Euclides da Cunha | 22 |
| Ariano Suassuna | 22 |
| Patativa do Assaré | 21 |
| Maria do Rosário Gregolin | 21 |
| Ismail Xavier | 21 |
| Maura Penna | 21 |
| Michel de Certeau | 20 |
| Luiz Paulo da Moita Lopes | 20 |
| Roger Chartier | 19 |
Destaca-se evidentemente a relevância do autor Durval Muniz de Albuquerque Jr., que aparece com uma numeração superior à própria totalidade de artigos mapeados (165) devido à presença de citações a mais de um dos seus trabalhos num único artigo. Além de A invenção do Nordeste e outras artes (1999), sua produção mais popular, outras obras de sua autoria como Nordestino: uma invenção do falo: uma história de gênero masculino (2003) e Preconceito contra a origem geográfica e de lugar: as fronteiras da discórdia também receberam menções expressivas. O historiador, inquestionavelmente, é a principal referência sobre Nordeste e nordestinos na academia.
Stuart Hall é o segundo autor mais citado nos trabalhos, sobretudo por suas obras A identidade cultural na pós-modernidade (2006) e Da diáspora: identidades e mediações culturais (2003). Assim como Tomaz Tadeu da Silva – cuja publicação Identidade e diferença: a perspectiva dos estudos culturais (2005) também foi bastante referenciada e consta, inclusive, com um texto de autoria de Hall –, são os teóricos mais populares neste campo para discutir a questão da identidade. Ainda que Zygmunt Bauman também faça parte desse jogo, com Identidade: Entrevista a Benedetto Vecchi (2005), o filósofo recebe mais atenção quanto à questão da modernidade.
Outro nome também bastante conhecido da comunidade acadêmica, Michel Foucault acumula pontos de modo razoavelmente equilibrado entre suas obras: Arqueologia do saber (1969), A ordem do Discurso (1970) e Microfísica do Poder (1978). Há de ser feita uma investigação mais profunda sobre qual é o diálogo que os autores promovem com o filósofo, no entanto, a partir da leitura de alguns resumos que o citam de modo específico, pôde-se identificar sobretudo as questões que envolvem relações de poder e a ênfase na Análise do Discurso enquanto abordagem teórico- metodológica desenvolvida por vários trabalhos.
Esse campo também ganha corpo com a presença notória de nomes como Eni Pucicinelli Orlandi, Michel Pêcheux, Maria do Rosário Gregolin e Luiz Paulo da Moita Lopes. Os trabalhos desenvolvidos em diálogo com esses autores geralmente advêm da área de Comunicação, onde a Análise do Discurso é bastante popular para desenvolver pesquisa sobre produtos culturais/midiáticos. Por outro lado, sob uma perspectiva mais “culturalista”, autores como Mikhail Bakhtin, Néstor García Canclini, Homi Bhabha e Pierre Bourdieu oferecem os conceitos e um modo de pensar esses mesmos produtos a partir de contextualizações mais antropológicas e sociológicas.
Vale comentar ainda aqueles autores que oferecem o panorama teórico para discutir sobre a cultura brasileira e/ou nordestina de modo mais abrangente, liderados por Gilberto Freyre em suas diferentes publicações. Somam a essa lista Luís da Câmara Cascudo, Renato Ortiz, Antônio Cândido e Alfredo Bosi – esses últimos cujo trabalho se desenvolve bastante em cima da Literatura, área já referida como de bastante importância para as questões em cena aqui. Importante citar, nesse sentido, a presença de Euclides da Cunha, Ariano Suassuna e Patativa Assaré, que, assim como Freyre, são fontes e objetos de estudo dessas produções.
Considerações finais
A ideia do artigo surgiu a partir de uma demanda produtiva-pessoal do autor para com o desenvolvimento do seu projeto de mestrado. A proposta do trabalho foi realizar um levantamento exploratório das produções acadêmicas sobre o Nordeste e sobre os nordestinos quanto às questões de identidade e representação, de modo a esquematizar minimamente quais são as áreas e temáticas mais comuns para pensar – e teorizar – todas essas questões no ambiente acadêmico.
Como resultado desse processo, foi possível identificar que trabalhos sobre Cinema, Música e Literatura são recorrentes nas discussões sobre produções de sentidos e significados em torno de Nordeste e nordestinos. Uma análise com mais afinco da bibliografia dos trabalhos mapeados permitiu também identificar que o historiador Durval Muniz de Albuquerque Jr. é a autoridade no assunto, enquanto que teóricos como Stuart Hall, Michel Foucault, Tomaz Tadeu da Silva e Zygmunt Bauman fornecem o arcabouço conceitual para as discussões travadas.
Por fim, ressalta-se mais uma vez o caráter exploratório da pesquisa e as possibilidades de desdobramentos para um futuro trabalho. Expandindo a análise, seria possível pensar em investigar cada um dos campos/áreas temáticas principais, para identificar preferências teóricas ou de métodos; voltando o olhar para a bibliografia, seria possível também tensionar a lista de autores mais citados para discutir a popularidade de alguns específicos; ou, ainda, analisar o local da produção para pensar a relação autor-identidade-nordeste e a associação Nordeste x estados, para localizar os Nordestes sobre o qual estão discutindo.
Notas
- Mestrando no Programa de Pós-Graduação em Cultura e Territorialidades da Universidade Federal Fluminense (PPCULT/UFF).
- “Definidas como de caráter bibliográfico, elas parecem trazer em comum o desafio de mapear e de discutir uma certa produção acadêmica em diferentes campos do conhecimento, tentando responder que aspectos e dimensões vêm sendo destacados e privilegiados em diferentes épocas e lugares, de que formas e em que condições têm sido produzidas certas dissertações de mestrado, teses de doutorado, publicações em periódicos e comunicações em anais de congressos e de seminários. Também são reconhecidas por realizarem uma metodologia de caráter inventariante e descritivo da produção acadêmica e científica sobre o tema que busca investigar, à luz de categorias e facetas que se caracterizam enquanto tais em cada trabalho e no conjunto deles, sob os quais o fenômeno passa a ser analisado.” (FERREIRA, 2002, p. 258)
- Além da dimensão epistemológica, Hall (1997, p. 27) cita quatro dimensões gerais para discutir a centralidade da cultura: “a ascensão dos novos domínios, instituições e tecnologias associadas às indústrias culturais que transformaram as esferas tradicionais da economia, indústria, sociedade e da cultura em si; a cultura vista como uma força de mudança histórica global; a transformação cultural do quotidiano; a centralidade da cultura na formação das identidades pessoais e sociais”.
- “Colocando em termos simples, cultura diz respeito a “significados compartilhados”. Ora, a linguagem nada mais é do que o meio privilegiado pelo qual “damos sentido” às coisas, onde o significado é produzido e intercambiado. Significados só podem ser compartilhados pelo acesso comum à linguagem. Assim, esta se torna fundamental para os sentidos e para a cultura e vem sendo invariavelmente considerada o repositório-chave de valores e significados culturais.” (HALL, 2016, p. 18)
- Google Scholar: https://scholar.google.com.br/
- A coleta foi feita a partir da query de busca “identidade nordestina” OR (identidade AND nordeste) OR (representação AND nordestinos) OR (representação AND nordestinas) entre março e abril de 2019; e o critério de recorte foi a presença dos termos identidade(s), representação(ões), narrativa(s), sentido(s) ou cultura(s) no título ou resumo do trabalho, em consonância com o enfoque quanto às categorias-mães Nordeste/nordestino(as) (não específicas aos estados); foram desconsiderados trabalhos que não continham resumo (capítulos de livro, ensaios, etc.).
- A planilha está disponível online e pode ser acessada no link:
- Os termos “nordeste”, “nordestino(a)” e “nordestino(as)” foram removidos para melhor visualização. Optou-se por manter “identidade” e “representação” para perceber como essas duas terminologias aparecem – ou não – em categorias específicas.
- Software de análise de texto: http://www.laurenceanthony.net/software/antconc/
Referências bibliográficas
FERREIRA, Norma. Pesquisas denominadas estado da arte: possibilidades e limites. Educação e Sociedade, Campinas, v. 1, n.79, p. 257-274, 2002.
HALL, Stuart. A centralidade da cultura: notas sobre as revoluções culturais do nosso tempo. Educação & realidade, v. 22, n. 2, 1997.
HALL, Stuart. A identidade cultural na pós-modernidade. Rio de Janeiro: DP&A Editora, 2015.
HALL, Stuart. Cultura e representação. Rio de Janeiro: Ed. PUC-Rio, 2016.
PITOMBO, Mariella; RUBIM, Lindinalva; SOUZA, Delmira. ESTUDOS DA CULTURA NO BRASIL:
UMA ANÁLISE A PARTIR DO ENECULT. In: XI Encontro de Estudos Multidisciplinares em Cultura – XI ENECULT, 2015, Salvador. Salvador: CULT, 2015. v. 1.
WOODWARD, Kathryn. Identidade e diferença: uma introdução teórica e conceitual. In: Identidade e diferença: a perspectiva dos estudos culturais. Petrópolis, RJ: Vozes, p. 7-72, 2014.













 “O primeiro significado completo funciona como significante no segundo estágio do processo de representação e, quando ligado a um tema mais amplo pelo leitor, produz uma segunda mensagem, ou significado, mais elaborada e ideologicamente enquadrada”, explica Hall. Ou seja, é o primeiro significado (o signo de uma pessoa, um jovem negro, na capa de uma revista francesa, com roupas militares), que fundamenta a segunda interpretação – o militarismo/colonialismo francês sob povos africanos. “Barthes dá a esse segundo conceito ou tema um nome: ele o chama de ‘uma mistura a propósito do ‘imperialismo francês’ e do ‘militarismo’. Isto, diz ele, adiciona uma mensagem sobre o colonialismo francês e seus fiéis soldados filhos negros. Barthes chama esse segundo nível de significação de mito” (p. 72-73).
“O primeiro significado completo funciona como significante no segundo estágio do processo de representação e, quando ligado a um tema mais amplo pelo leitor, produz uma segunda mensagem, ou significado, mais elaborada e ideologicamente enquadrada”, explica Hall. Ou seja, é o primeiro significado (o signo de uma pessoa, um jovem negro, na capa de uma revista francesa, com roupas militares), que fundamenta a segunda interpretação – o militarismo/colonialismo francês sob povos africanos. “Barthes dá a esse segundo conceito ou tema um nome: ele o chama de ‘uma mistura a propósito do ‘imperialismo francês’ e do ‘militarismo’. Isto, diz ele, adiciona uma mensagem sobre o colonialismo francês e seus fiéis soldados filhos negros. Barthes chama esse segundo nível de significação de mito” (p. 72-73).



 “O fechamento da API de Páginas eliminou todos acessos ao conteúdo do Facebook conforme acordado em seus Termos de Serviço. Permita-me sublinhar a magnitude dessa mudança: não há atualmente uma maneira para extrair de forma independente o conteúdo do Facebook sem violar seus Termos de Serviço. Num estalar de dedos metafórico, o Facebook invalidou instantaneamente todos os métodos que dependiam da API de Páginas. […] Nós nos encontramos numa situação na qual o investimento pesado em ensinamento e aprendizado de métodos específicos da plataforma podem se tornar obsoletos do dia para a noite: é isso que quero dizer com ‘a era pós-API’.”
“O fechamento da API de Páginas eliminou todos acessos ao conteúdo do Facebook conforme acordado em seus Termos de Serviço. Permita-me sublinhar a magnitude dessa mudança: não há atualmente uma maneira para extrair de forma independente o conteúdo do Facebook sem violar seus Termos de Serviço. Num estalar de dedos metafórico, o Facebook invalidou instantaneamente todos os métodos que dependiam da API de Páginas. […] Nós nos encontramos numa situação na qual o investimento pesado em ensinamento e aprendizado de métodos específicos da plataforma podem se tornar obsoletos do dia para a noite: é isso que quero dizer com ‘a era pós-API’.”