Acho importante começar este post falando que o que vou trazer aqui não é uma regra ou realidade absoluta. É como um guia de conduta que eu, pessoalmente, fui aos poucos organizando para mim mesmo a partir de vários materiais que fui consumindo ao longo dos anos e também a partir de diversos feedbacks/devolutivas que tive a oportunidade de receber durante a minha carreira. Espero que possa ser útil para outras pessoas como foi e tem sido útil para mim nessa trajetória de profissional de análise e inteligência de dados.
Dito isso, o meu intuito aqui é compartilhar algumas dicas e instruções de como eu abordo a produção de relatórios, pensando esses produtos como uma entrega de inteligência que deve guiar tomadores de decisões a um caminho mais assertivo a partir dos dados que foram analisados. Tão importante quanto a metodologia, o critério de análise, o aprofundamento nos dados ou a qualidade das informações transmitidas, a meu ver, é também o modo como transmitimos essa inteligência para outras pessoas que só chegam no final de todo o processo.
Afinal, quando uma empresa, seja uma marca ou agência, contrata um serviço de relatoria – seja ele de listening/monitoramento, performance de mídia, web analytics ou o que quer que seja -, ela não o fez pelo relatório, mas sim pelos insights que dali podem surgir. A “entrega” pode até ser materializada num relatório em formato de PPT, PDF, DOC ou um dashboard (e geralmente é), mas o que estão pagando de verdade é pelas informações que esses materiais podem trazer para guiar uma ação posterior – um criativo, um desenvolvimento de produto, um ajuste de investimento etc.
Ainda nesse contexto, o ritmo de trabalho e fluxo de informações (e dados) aos quais a grande maioria – senão a totalidade – desses profissionais que consomem relatórios estão condicionados também acrescenta a esse cenário uma dificuldade mais ampla à apresentação de resultados. Imagine que essas pessoas demandantes provavelmente não estão consumindo apenas um relatório, mas diversos materiais, dentre relatórios internos, da Kantar, IPSOS, Google, Meta, WGSN, TrendWatching, BOX1824 etc. com dezenas ou centenas de páginas.
Torna-se, portanto, um esforço também dos profissionais que produzem relatórios (de listening, pesquisa, performance de mídia, web analytics etc.), encontrar maneiras de facilitar a absorção de todo o conteúdo que precisa ser compartilhado – ou pelo menos daquilo que é mais importante/decisivo. É por isso que fui desenvolvendo, aos poucos (novamente, a partir de feedbacks e estudo), um modus operandi que preza muito por três pilares que considero o sustento de todo bom relatório: design, dataviz e storytelling.
DESIGN NÃO É “SÓ” SOBRE ESTÉTICA
Quando eu trabalhava no IBPAD, alguém me apresentou o Polling Data, um projeto incrível liderado por um dos estatísticos mais respeitados do mercado de pesquisa de opinião no Brasil. Na época das eleições, “agregava” diversas pesquisas eleitorais para desenvolver uma metodologia própria que ponderasse os diferentes cenários de cada pesquisa dado os vieses que elas mesmas apresentavam. É, sem sombra de dúvidas, umas das iniciativas mais interessantes que eu já vi do ponto de vista metodológico e de crítica analítica.
No entanto, apesar de sempre trabalhar também com um ótimo dataviz, apresenta um design que não dialoga com a internet (e o mundo digital) que vivemos em 2023. E isso não é uma crítica pela crítica, mas uma constatação para argumentar que, nos dias de hoje, estética também passa credibilidade. Em tempos de fake news e golpes via internet, a maioria das pessoas – desse mercado ao qual me refiro, obviamente – já desenvolveu um olhar mais atento inclusive na estética das coisas, seja um site, um app ou um e-mail, para julgar o quão “verídico” aquilo se parece.
Ou seja, um material “feio” pode dar a impressão de um trabalho desleixado, mau feito e amador – portanto, com menos credibilidade. Apenas para fins comparativos, podemos tomar, como exemplo, o projeto The Perception Gap, que também é um projeto político, mas que dedicou um esforço maior ao trabalho de UI Design. Isso quer dizer que o TPG é melhor, analiticamente falando, do que o Polling Data? Não, mas a confiança e a usabilidade – pensando aqui em algo que facilita a absorção das informações – que o primeiro apresenta ao leitor é notavelmente mais amigável.
Além de passar mais credibilidade, portanto, a preocupação com o design também endereça o problema da sobrecarga de informações: artifícios ou indumentárias estéticas podem ajudar o leitor a direcionar seu olhar para aquilo que (num slide) é mais importante. E isso não significa que todos nós que trabalhamos com análise de dados (e já precisamos aprender a mexer em 50 ferramentas e ainda a programar em pelo menos duas linguagens de programação diferente) também precisamos aprender design, mas alguns direcionamentos básicos já podem ajudar.
A thread about using fonts/typography in presentations. Decisions about text matter. Just as you can speak the same word in many ways, the way you write text can affect communication, emotion, and attitude. 🧵1/19 pic.twitter.com/e4PPu2D5Vq
— @IAmSciComm – On a Break! (@iamscicomm) May 31, 2022
Essa thread acima, por exemplo, mostra como o simples uso de diferentes fontes pode causar um impacto considerável na sua apresentação (ou no seu relatório). Também dá dicas de algumas customizações textuais que são mais ou menos difíceis de ler, alguns artifícios simples como um espaçamento diferenciado e alteração do tamanho das fontes que podem facilitar a leitura, além de outras orientações interessantes referentes a espaçamento, diagramação, extensão de texto, etc. São mudanças “simples” que facilitam muito a absorção das informações.
DATAVIZ
Outro pilar bastante importante e que acredito que talvez seja o mais coletivamente discutido dentre os três que listo é o famoso dataviz – ou visualização de dados, em boa tradução. De modo simples, é o esforço em encontrar a melhor forma para apresentar os dados analisados – destacando padrões, resumindo e comunicando números e apresentando informações. Dialoga muito com a questão do design, como podemos ver na apresentação a seguir, produzida por Julie Teixeira, uma das minhas primeiras referências no assunto e que continuo recomendando para vários colegas.
Nesse outro material, do blog Datawrapper, a autora Lisa Charlotte Muth indica quais fontes usar para gráficos e tabelas. Entra ainda em mais detalhes sobre fontes para explicar como cada uma funciona ou não para o tipo de visualização que está sendo cogitada, com vários exemplos destrinchados à minúcia. Embora a sua preocupação seja com dataviz mesmo, é um bom exemplo de como um também depende do outro. Novamente, não que haja uma necessidade em se estudar tipografia, mas como alguns conceitos e entendimentos básicos podem ser bastante úteis.
Existe uma avalanche de textos e materiais diversos sobre dataviz na internet à disposição, o que pode parecer um pouco sufocante e angustiante – como se você não fosse nunca conseguir aprender tudo que deveria, mas, novamente, o básico já é mais do que suficiente. Essa colinha da consultoria InfoNewt, especializada em melhorar a comunicação das empresas no contexto de técnicas e inovação de visualização de dados, por exemplo, já oferece alguns caminhos interessante para como apresentar porcentagem. Já o diagrama abaixo é uma tradução do IBPAD também bastante útil.
Também no blog do IBPAD, o professor Robert McDonnell oferece outras dicas simples (e fundamentais) para visualização de dados: sempre que possível, facilitar a comparação entre as categorias; usar cores de modo a informar categorias ou padrões; de preferência, não utilizar rótulos angulados, mas (quando necessário) garantir que tanto rótulos quanto anotações estarão no gráfico; e, por fim, tomar cuidado com os limites dos eixos para que ao mesmo tempo não pareça “maquiar” a realidade mas que também ajude a destacar o que precisa ser passado.
A série Remove to Improve do Dark Horse Analytics também mostra de maneira simples como nós complicamos – ou os próprios softwares complicam – a criação de gráficos, com o simples lema de: menos é mais. Mostra como detalhes simples como arredondar valores, remover rótulos redundantes, bordas e linhas pode fazer toda a diferença. Além desse material simples, fica a recomendação também dos sites RAWGraphs e Flourish, que dispõem de uma variedade de gráficos possivelmente interativos além de um fluxo de construção facilitada a partir da base que existe à disposição.
Por fim, pessoalmente, deixo aqui apenas mais uma opinião sobre dataviz: nem sempre é o gráfico mais bonito ou mais complexo que garante que as informações serão melhores transmitidas. Acho que é muito fácil para profissionais de dados caírem na tentação de querer sempre fazer um gráfico mais difícil que o outro, justamente para mostrar suposta habilidade com tal ferramenta ou método. O melhor gráfico é aquele que é útil, eficaz: quem vai ler consegue captar a informação? Se sim, perfeito. Pode ser um gráfico de barra ou até o polêmico gráfico de pizza (para até duas variáveis).
COMO VOCÊ QUER CONTAR ESSA HISTÓRIA?
Outra hypeword usada e desgastada exaustivamente no mercado é o tal do storytelling. É uma palavra que, imagino eu, veio de outras disciplinas bem distantes da nossa, mas que o mercado – sobretudo publicitário – adotou quando percebeu a importância da economia da atenção. Com tanto conteúdo, filme, série, site, vídeo no YouTube, vídeo no TikTok, notícia, artigo de opinião e, também, relatórios por aí, é de se esperar que diferentes profissionais estejam cada vez mais se preocupando com talvez uma das características mais básicas do ser humano: como contar boas histórias.
No contexto de apresentação de relatórios em análise de dados, contar boas histórias significa principalmente compreender as estratégias discursivas necessárias para capturar a atenção qualificada do leitor. E isso pode ser feito de diversas maneiras, inclusive usufruindo de técnicas de design e dataviz bem elaboradas, como destaquei nos pontos anteriores. O storytelling, aqui, é quem amarra tudo: é o fio condutor que, entendendo qual é o contexto, quem é a audiência e o que ela espera dessa entrega, dirige pelo caminho mais adequado para que a inteligência seja transmitida da melhor forma.
Refletindo sobre isso no ano passado, percebi que as histórias que nós, profissionais de análise de dados, temos que contar não são narrativas, mas dissertações. Lembra nas aulas de Redação quando a professora explicava que a classe dissertativa apresentava um problema o qual deveria ser discutido e geralmente resolvido com alternativas no texto? É bem parecido com o que somos contratados para fazer: endereçar/resolver problemas e/ou responder perguntas apresentando caminhos possíveis de solução, a partir de diferentes metodologias (e talvez aqui esteja a maior diferença da Redação).
É a mesma lógica também da pesquisa acadêmica: apresenta-se um problema que o pesquisador precisa analisar, discutir ou resolver de algum modo dentro da sua disciplina de estudo. A diferença, aqui, é que há um grande investimento (justificado) na metodologia e processo da análise, algo que na Redação do colégio é deixado de lado pela falta de instrumentos (criamos soluções a partir das nossas cabeças ou dos textos ali à disposição) e que no mercado o interesse maior está nas soluções criadas, mesmo que seja importante passar por como chegamos nesses insights.
Devido a minha trajetória profissional, de alguém que se criou dentro de um instituto de pesquisa e que ao mesmo tempo passou por uma graduação e mestrado com uma veia bastante acadêmica, demorei muito tempo para entender essa lógica. Passei muito tempo da minha vida preocupadíssimo em explicar, num relatório, toda a metodologia desenhada, ou aprofundar uma análise que, dando dois passos para trás e entendendo melhor o contexto da demanda, não faria muita diferença para o cliente. Foi uma virada de chave importantíssima para mim.
Hoje eu entendo e argumento que o storytelling de um relatório pode ser mais relevante do que os dados ou a análise em si. Quando digo isso, estou querendo dizer que o modo como os resultados serão apresentados através de artifícios de design e dataviz que facilitem a compreensão de quem vai absorver essas informações para atuar em tomadas de decisões mais assertivas pode ser mais importante do que uma análise mega complexa ou com uma metodologia super difícil. No fim do dia, independente das cento e poucas páginas, as empresas querem só os insights – e tudo bem.
A dica que eu dou e que levo para mim é sempre tentar entender duas coisas básicas: quem vai ler/consumir esse relatório e de que forma? A partir disso, você consegue pensar qual é o melhor fio condutor para apresentar essa história. Um relatório apresentado deve ser muito diferente de um relatório enviado por e-mail, assim como um relatório que chega à diretoria e gerência deve também ser muito diferente de um relatório que chega a coordenadores, supervisores e analistas de outras disciplinas, como criativos, por exemplo.
Para finalizar, então, só algumas dicas avulsas que tenho para mim e acho que podem ajudar:
Colocar no rodapé ou cabeçalho o nome do relatório, responsáveis pela produção e, em casos específico, o período ao que se refere a análise;
Idealmente, escrever textos com o mínimo de linhas possíveis – sempre tento que não passem de 3 ou 4 linhas, senão já se torna uma leitura que parece “pesada”;
Destacar números e e informações mais relevantes em cada slide, para facilitar e guiar o olhar de quem possivelmente fará apenas uma leitura dinâmica;
Não deixar nenhum dado solto ou descontextualizado – ou seja, explicar todos os picos/depressões, crescimentos, todo padrão que se quebre de alguma forma;
Também em relação aos dados, sempre apresentar um referencial – um número sozinho pode ser muito, pouco, igual, ou seja, trazer sempre comparativo histórico ou categórico;
Costurar os achados do relatório como num site, literalmente linkando as informações para criar uma coesão da história que está se desenvolvendo.
Segundo seu próprio site, o Rock in Rio é um dos maiores festivais de música do mundo, somando uma audiência de mais de 10 milhões de pessoas em sua história. Porém, não é só na Cidade do Rock que o espetáculo acontece: desde sua retomada em solo brasileiro no ano de 2011, o Rock in Rio é evento também nas redes sociais digitais, utilizadas pelos usuários para comentar não apenas os shows (transmitidos em tempo real numa mega cobertura fornecida pelas empresas do Grupo Globo), mas também todos os bastidores – seja a estadia dos artistas internacionais no Brasil, a presença de celebridades nacionais na área VIP do festival, ou ainda os inusitados acontecimentos na plateia.
Em 2022, primeira edição após o hiato imposto pela pandemia, a repercussão foi ainda maior: dados do Observatório da TV mostram que este foi o ano com maior audiência televisiva desde a volta do festival para o Brasil na TV aberta, ou seja, sem contar com aqueles que assistiam a cobertura pelo canal Multishow, Canal Bis ou pelo streaming Globoplay, que estava com acesso liberado para assinantes e não assinantes. E, num movimento já comum a grandes eventos televisionados, parte significativa desses milhares de espectadores comentavam tudo o que viam pelo Twitter, fazendo o Rock in Rio ficar entre os assuntos mais comentados do mundo em todos os dias de show.
Ao final do evento, o jornalista José Norberto Flesch, notório nas redes pelos seus conteúdos sobre o mundo da música, fez as seguintes perguntas aos seus seguidores:
Qual foi a maior surpresa do Rock in Rio (não necessariamente o melhor show)?
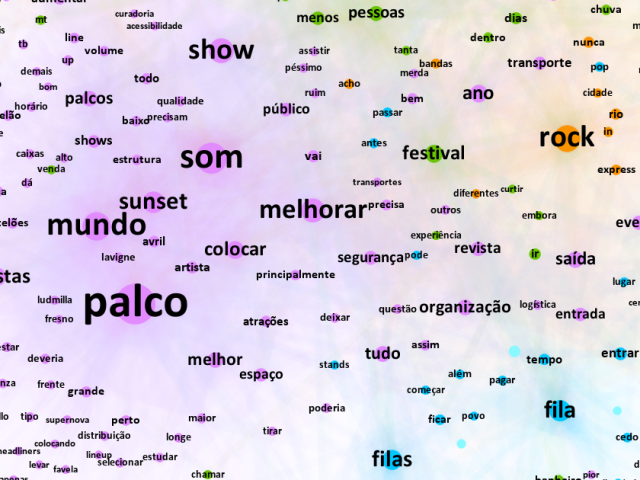
Considerando as centenas de replies a cada um dos tweets, bem como a pertinência de Flesch para os fãs de música usuários da rede, entendemos essas interações como valiosas para ilustrar – de forma evidentemente generalizada – as críticas e elogios sobre o Rock in Rio 2022. Assim, no dia 13 de setembro coletamos as 5.784 respostas postadas até então e as organizamos em duas redes semânticas, conforme metodologia de análise textual proposta por James A. Danowski (1993). Os dados foram processados no WORDij, desenvolvido pelo próprio Danowski, para a observação de paridades e co-ocorrências de palavras. Em seguida, o resultado foi trabalhado no software Gephi para a criação de grafos que facilitem e dinamizem a visualização das linhas discursivas encontradas.
Para a leitura desses mapas, considera-se cada nó (círculo colorido) como correspondente a uma palavra e as arestas (linhas) entre eles como as ligações encontradas. O tamanho do nó equivale ao número de co-ocorrências do termo; a largura da aresta indica o grau da paridade; as cores indicam clusters, agrupamentos temáticos identificados pelo próprio programa; e quanto mais central o nó, maior o número de ligações. Para fins didáticos, destacamos em nossa análise os termos presentes nos grafos através das aspas.
Para a primeira pergunta, acerca das surpresas do Rock in Rio, coletamos 493 respostas (dentre replies e quotes). Por ser um número reduzido e, em geral, trazer respostas mais objetivas, optou-se por delimitar em quatro o número de palavras na janela de paridade, ou seja: a cada palavra, se formava uma ligação com as quatro palavras identificadas à sua frente ou atrás.
Qual foi a maior surpresa do Rock in Rio (não necessariamente o melhor show)? – respostas ao tweet de José Norbert Flesch
Como de se esperar, o principal assunto dentre os comentários positivos se referem aos “shows”. Dentre estes, o de “Måneskin” aparece em evidência, com os respondentes afirmando sem “dúvida” o destaque e justificando a “surpresa” porque não “conheciam” a banda antes do festival e “acharam” o show “bom”. A banda italiana é também citada em associação a outros shows, como o de “Luisa Sonza”, “Djavan”, “Post Malone” e “Green Day”.
Com uma apresentação cheia de declarações de afeto ao público brasileiro, a audiência afirma que não “esperava” “nada” de “Camila Cabello”, mas que a mesma entregou “tudo”. Outras demonstrações de carinho ao público mencionadas foram ter a banda “Coldplay” “cantando” a música “Magic” em “português”, e a cantora “Rita Ora” convidando “Pabllo Vittar” para o palco com ela.
Em tom bem-humorado, muitos comentaram como, após toda a polêmica, a “maior” “surpresa” foi o fato de “Justin Bieber” “realmente” ter “aparecido” para seu show.
Outros artistas citados foram “Ludmilla”, “Jessie J”, “Billy Idol”, “Avril Lavigne” – destaque do “palco” “sunset” – e a banda “Bastille”.
No mais, em relação à infraestrutura, aqueles que compareceram ao evento elogiaram os “banheiros” “sempre” “limpos”.
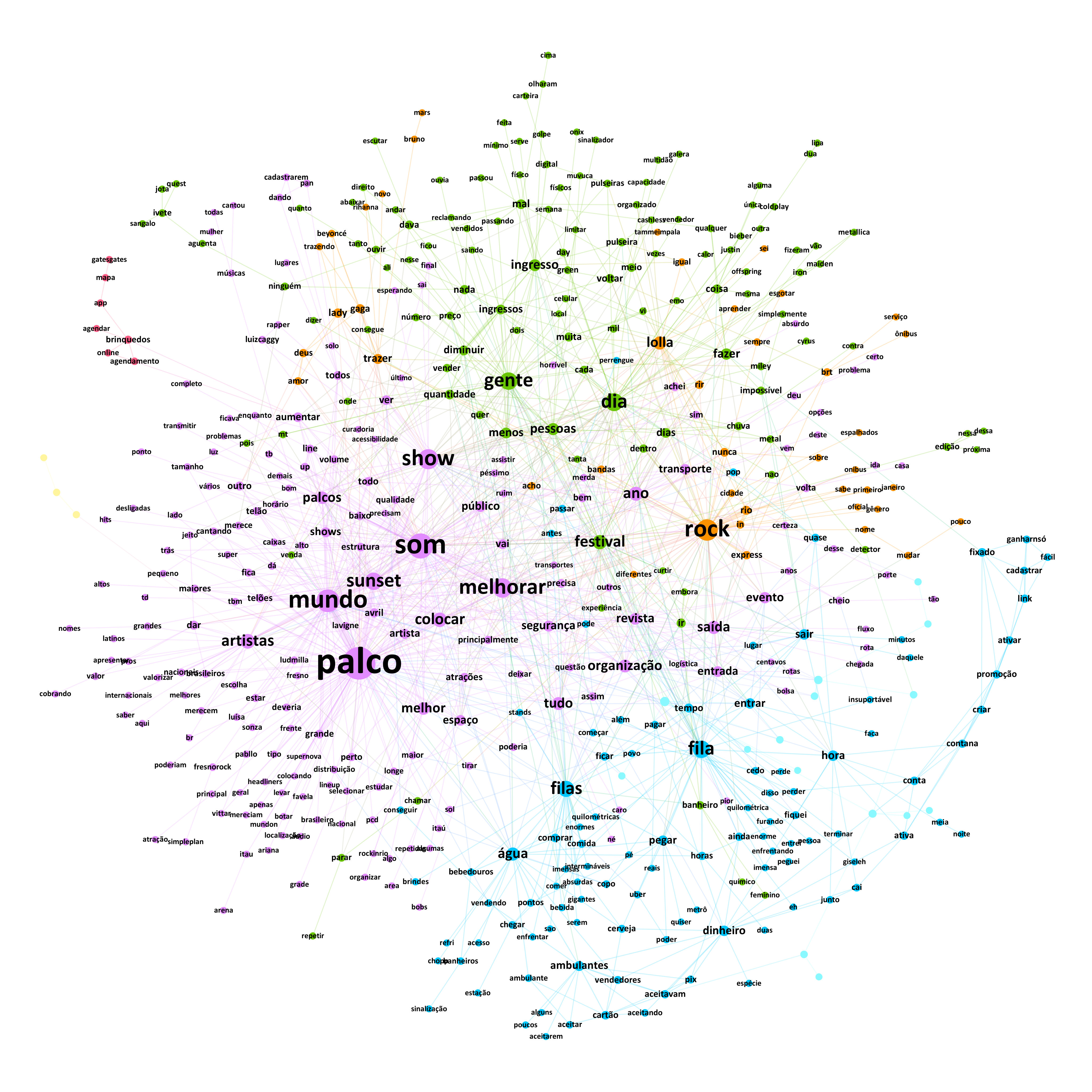
Em oposição direta às “surpresas”, as respostas referentes às “decepções” eram mais elaboradas, além de numerosas: neste tópico, somaram-se 2.926 tweets (dentre replies e quotes), que originaram a rede a seguir. Devido ao maior volume, refletido no tamanho e complexidade do grafo, optou-se pela janela de paridade padrão de três palavras.
Qual foi a maior decepção do Rock in Rio (não necessariamente o pior show)? – respostas ao tweet de José Norbert Flesch
O cluster rosa, maior da rede, agrupa termos relacionados aos shows. É interessante notar que os nomes mais próximos ao par “Palco Mundo” são “Ludmilla”, “Avril Lavigne”, que se apresentaram no “Palco Sunset”, e “Fresno”, que participou na “Arena Itaú” a convite do TikTok. Isso indica uma clara insatisfação por parte dos fãs com o local onde os ídolos tocaram, originando demanda para a organização “colocar” esses “artistas” como “atração” do palco principal, onde, devido a suas carreiras, os fãs acreditam que “poderiam”, “deveriam” e “merecem” “estar”. Apesar de mais afastadas, “Luisa Sonza” e “Pabllo Vittar” também são mencionadas nessa reivindicação, indo ao encontro de pedidos para que o Rock in Rio passe a “valorizar” mais artistas “nacionais” (“brasileiros”/“br”) e “latinos”.
Ainda sobre as “atrações”, houve reclamações sobre “algumas” serem “repetidas” no evento, que se torna todo “ano” a “mesma” “coisa”. Por exemplo, mencionam que “ninguem” “aguenta” ou “merece” mais a presença de “Jota Quest” ou “Ivete Sangalo”. Sugerem, então, que a organização possa “estudar” e “selecionar” “melhor” os “artistas” para as próximas edições, de modo a “trazer” “bandas” “diferentes”, citando “Bruno Mars”, “Beyoncé”, “Ariana Grande”, “Rihanna”, “Miley Cyrus” e “Lady Gaga” – esta última ligada a nós que indicam a súplica pelo “amor” de “Deus”.
Além das atrações em cima deles, os “palcos” também foram criticados pela “estrutura”: para quem compareceu ao festival, o “som” estava “baixo” “demais” (“super”), “principalmente” no “Palco Sunset”, que, por sua vez, levou sugestões para que possam “aumentar” tanto em seu “tamanho” quanto no “volume” e “qualidade” do som. Segundo os usuários, ambos os palcos também poderiam contar com “telões” “maiores”.
“Melhorar” corresponde a um grande nó, identificando pedidos para aprimorar o “transporte”, particularmente o “Rock in Rio Express” (“BRT”, “serviço” de “ônibus”); a “segurança”, principalmente na “revista” durante a “entrada”; na “logística” tanto para “entrar” quanto para “sair” na “volta” para “casa”; a “acessibilidade”; e na “organização” das “enormes”, “quilométricas”, “absurdas”, “gigantes” e “intermináveis” “filas” – seja para os “banheiros”, para os “bebedouros” de “água”, para “comer” ou “comprar comida”, ou mesmo para “pegar” “brindes” nos “stands”.
Contudo, o festival também não agradou ao restringir o acesso aos “brinquedos” do local unicamente através de “agendamento” prévio realizado “online” no “app”, numa clara tentativa de diminuir as filas. Ademais, sugeriu-se que os shows pudessem “começar” e “terminar” mais “cedo” e, para além das ossadas do evento, houveram reclamações acerca de “alguns” “cambistas” que “ainda” não “aceitavam” pagamento via “pix”.
O grande “quantidade” de “gente” num mesmo “local” incomodou não apenas nas filas, com “pessoas” “passando” “mal” no “meio” da “multidão”, ou reclamando que “mal” “dava” para “andar”, “ver” ou “ouvir” “nada” “direito”. Dessa forma, algumas respostas sugerem “diminuir” o “número” de “ingressos” “vendidos” por “dia”, além do “preço” dos mesmos. Sobre os ingressos, também foi sinalizado um “golpe” aplicado na compra da versão “digital”, como no “Lolla”, evento ao qual o Rock in Rio foi comparado.
A separação de “gêneros” musicais, tendo, por exemplo, um “dia” dedicado ao “pop” e um ao “emo” não agradou os fãs de “rock”, que pedem para a organização “mudar” o “nome” “oficial” do Rock in Rio.
As 2.365 respostas ao último tweet ofereceram uma rede bastante semelhante à segunda, resultado intuitivamente esperado tendo em vista que o que não agradou é o mesmo que deve ser aprimorado.
Em que o Rock in Rio pode melhorar para a próxima edição? – respostas ao tweet de José Norbert Flesch
Essa correspondência quase simétrica entre os retornos à segunda e à terceira pergunta feita por Flesch é interessante por comprovar as insatisfações do público mas também do ponto de vista da aplicação metodológica, uma vez que comprova a efetividade da metodologia de análise de redes semânticas ao analisar conteúdos textuais diferentes mas com uma mesma linha discursiva geral.
Referências
Danowski, J.A. (1993). Network analysis of message content’. In: Barnett, G. & Richards, W. (eds.): Progress in communication sciences XII, pp.197-222, Ablex, Norwood, NJ.
Uma das grandes perdas do mercado brasileiro de inteligência de mídias sociais nos últimos anos tem sido, sem dúvidas, a ausência de uma pesquisa que mapeie questões relevantes para profissionais, agências, clientes, ferramentas e todas as demais partes envolvidas. Lá fora, o The Social Intelligence Lab retomou este ano uma pesquisa sobre o estado do social listening que não acontecia desde 2019, antes da pandemia mudar pra sempre a nossa relação com a internet e com as marcas.
Apesar do crescimento do uso do social listening, ainda há muito que não sabemos sobre como as empresas estão utilizando-o e o impacto que ele tem em seus negócios. Esta pesquisa foi desenhada para compreender como a prática profissional de social data anlytics progrediu nos últimos três anos. Mais especificamente, queríamos descobrir os objetivos das empresas com dados de mídias sociais e até que ponto elas estão construindo uma estratégia de social listening ao redor deles. Dados de mídias sociais são utilizados de modo diferente a depender do nível de maturidade do social listening da empresa, desde extrair métricas de vaidade até definir casos de uso estratégicos e a longo prazo. Nós queríamos entender como os níveis de maturidade mudaram desde 2019.
p. 1
A pesquisa rodou entre março e abril de 2022, com mais de 350 profissionais de social intelligence respondendo ao questionário sobre suas práticas, desafios e opiniões para o futuro da indústria. Pessoas de diferentes países e em diferentes níveis de experiência dentro de marcas, agências e organizações participaram. Para qualificar as respostas, foram excluídas as de profissionais que trabalham em fornecedores de tecnologia (ferramentas, por exemplo), fechando 197 respondentes.
Sobre os respondentes:
41% são da Europa, 30% dos Estados Unidos e 20% da Ásia;
Quase 50% dos respondentes trabalham para empresas com mais de 1.000 funcionários;
46% são de empresas envolvidas nas seguintes indústrias: Research & Insight, Marketing & Advertising ou Technology;
77% dos respondentes trabalham em empresas B2B;
25% dos respondentes trabalham com dados de mídias sociais há mais de 10 anos, sendo 47% em cargos de Gerente, Diretor ou C-Level;
61% dos respondentes trabalham em cargos de Research & Insight ou Social Listening/Intelligence (contra 32% de 2019)
Perguntas que a pesquisa endereça:
As empresas estão construindo ferramentas próprias ou estão utilizando tecnologias já existentes para coletar e analisar dados de mídias sociais?
Quanto de análise manual está sendo feita x depende de IA e outras tecnologias para fornecer insights?
Como os desafios do social listening evoluíram?
As empresas ainda consideram um desafio tecnológico, por exemplo, encontrar as ferramentas certas para fornecer os melhores insights?
Profissionais de social listening ainda têm dificuldade diante de líderes e organização para mostrar o valor do seu trabalho?
O relatório está dividido em capítulos: primeiro, uma carta da Dr. Jillian Ney (fundadora do The Social Intelligence Lab) falando sobre a pesquisa; depois, uma seção para a metodologia contendo informações importantes sobre o público que participou; em seguida, os capítulos com os resultados alternam-se com textos dos patrocinadores – os quais destaco os de Jeremy Hollow (Listen+Learn) e de Jack Cuyvers (Convosphere), que achei que trouxeram provocações e análises bem interessantes.
ESCOLHENDO AS FERRAMENTAS E TECNOLOGIAS CERTAS
Os primeiros resultados trazem informações sobre a relação entre os profissionais e as principais ferramentas de social listening que utilizam, além de possíveis tecnologias que também auxiliam o trabalho. É uma seção importante para as ferramentas lá de fora, visto que 90% disseram ter uma influência significativa ou a palavra final na compra dessas soluções tecnológicas – e a pesquisa indica que o investimento nessas ferramentas segue crescendo (33% gastam mais de 100K todo ano).
Um dos “problemas” que o relatório aponta é a utilização de mais de uma ferramenta pela mesma empresa/agência: em 2019, 85% dos respondentes investiam em mais de uma solução para dados de mídias sociais e 45% queria reduzir o número de fornecedores. Em 2022, 81% dos respondentes continuam utilizando mais de uma ferramenta, sendo a média 2 ou 3 a resposta mais popular (55%) dentre os respondentes – e mais de três a resposta mais comum para empresas enterprise.
QUAIS FERRAMENTAS DE DADOS DE MÍDIAS SOCIAIS VOCÊ UTILIZA REGULARMENTE?
Sprinklr (47.4%)
Brandwatch (39.9%)
Talkwalker (15.9%)
Netbase (11.7%)
Audiense (10.7%)
Meltwater (8.9%)
Synthesio (7.5%)
Ferramentas internas próprias (5.6%)
Linkfluence (5.1%)
Social Studio (4.7%)
Embora tenha sido citada como a ferramenta mais popular, quase sempre apareceu junto a outras ferramentas, enquanto Brandwatch, Talkwalker e Netbase foram as mais populares dentre aqueles que responderam apenas uma ferramenta: “Essa descoberta parece refletir o testemunho de que, embora empresas enterprise procurem soluções all-in-one, constantemente acreditam que o elemento de social listening de ‘social suites’ [como a Sprinklr] não são poderosos o suficiente para as suas necessidades”.
QUAIS AS CINCO FEATURES DE TECNOLOGIAS DE ANÁLISE DE MÍDIAS SOCIAIS MAIS IMPORTANTES?
Cobertura de fonte de dados (64.5%)
Qualidade e relevância dos dados (68.4%)
Segmentação e categorização de dados (42.6%)
Regiões geográficas e línguas (40%)
Filtragem e ordenação de dados (34.2%)
Análise de sentimento (31%)
Exportação de dados (30.3%)
Métricas rastreadas (30.3%)
Análise de audiência (29.7%)
Capacidades de aprendizado de máquina / inteligência artificial (24.5%)
Preço (19.4%)
Integrações de API (14.8%)
Alertas e notificações (12.9%)
Compartilhamento de dashboards (11%)
Atendimento e gestão de conta (10.3%)
Relatórios automáticos (9.7%)
Importação dos dados (4.5%)
Análise de emoções (5.8%)
Algumas das primeiras respostas das funcionalidades mais importantes das ferramentas apontam para uma limitação intrínseca ao social listening: nós dependemos das APIs das mídias sociais. Isso afeta tanto a cobertura quanto a “qualidade e relevância dos dados”, diretamente ligada ao listening enquanto metodologia de pesquisa. Por isso as respostas abertas citavam a ausência de coleta de plataformas importantes (LinkedIn, TikTok, Quora) e categorização por geografia.
Finalizando esta seção, o relatório ainda revelou que 37% dos respondentes pretendem investir mais em novas tecnologias de análise de dados de mídias sociais (contra 8% em 2019) e 36% pretendem desenvolver uma atuação ou um centro de excelência de social listening centralizada/o (contra 17% em 2019): “Esses resultados sugerem que, desde a última pesquisa, mais empresas investiram em funcionários in-house e agora estão começando a levar análise de dados de mídias sociais mais a sério”.
TRABALHANDO COM DADOS DE MÍDIAS SOCIAIS E DA INTERNET
Há várias fontes de dados de mídias sociais diferentes, mas nem todas serão relevantes para o problema que você está tentando resolver. Se você conseguir entender as diferentes característica de cada fonte, e os potenciais insights que elas guardam, você pode reduzir a quantidade de dados que você precisa. E é isso que as empresas que possuem uma prática mais madura de social listening compreendem. Quando analisamos as fontes de dados mais importantes para profissionais de social intelligence, nós descobrimos que fóruns, sites de review e dados de busca apareceram no top5, atrás do Twitter e Instagram […]. Essa variedade sugere que profissionais de social listening estão caminhando para além de monitorar apenas canais proprietários das marcas nos maiores sites de redes sociais. Em vez disso, estão ampliando suas visões para canais onde consumidores estão tendo conversações que não são necessariamente sobre as marcas. Isso mostra um nível maior de maturidade na prática de social intelligence.
p. 11
O segundo capítulo de resultados começa com uma aspas fortes, as quais fiz questão de sublinhar aqui. Ao mesmo tempo que, de certo modo, endereça alguns dos problemas ou das limitações citadas para as próprias ferramentas de listening, também aponta para um caminho que a grande maioria das empresas brasileiras não percorrem. Aqui, entretanto, é importante relembrar que a maioria dos respondentes trabalham com pesquisa, o que pode justificar alguns dos resultados nesta e na próxima seção.
Em resumo, continua a abordar as problemáticas já listada nas limitações: fonte e qualidade dos dados. Twitter aparece como plataforma mais importante (talvez pela facilidade da coleta via API), seguida do Instagram e de fóruns – algo não muito comum no Brasil. Outro ponto não tão comum (até onde eu sei) para os brasileiros é justamente a questão da qualidade dos dados e toda a discussão sobre a limpeza da coleta (manual ou com queries) – algo citado como um dos principais desafios para os respondentes.
O quão importante são as seguintes fontes de dados em termos de relevância para a sua organização
O fantasma do fechamento das APIs também marca presença no relatório: 56% dos respondentes estão preocupados em não conseguirem mais acesso às fontes de dados de mídias sociais no futuro. Conectando isso com as respostas da plataformas mais relevantes e o fato da maioria dos respondentes trabalharem com pesquisa, compreende-se a alternativa por dados de fóruns, sites de review e dados de busca – por isso, também, a discussão sobre qualidade e limpeza dos dados.
Os resultados da pergunta sobre a junção dos dados de mídias sociais com outros dados é interessante porque bagunça um pouco essa constatação do público ser de pesquisa: web analytics aparece em 2º, enquanto transcrições de focus group e entrevistas estão na lanterna. Por outro lado, dados de pesquisa aparece como a opção preferida, o que faz sentido e aponta também em direção a compreender o comportamento dos usuários na internet.
Você mistura dados de mídias sociais com alguma outra fonte de dados alternativa?
A seção termina com uma importante discussão sobre ética e privacidade, além de uma breve citação a bots e mis/dis-information. “Ao observarmos como os respondentes descrevem os passos que tomam para cumprir com privacidade e ética, há um pouco mais de foco em cumprir com regulações de privacidade do que garantir práticas éticas”, constata. “Isso destaca a falta de guias formais para a indústria de social listening quando se trata de trabalhar com dados”.
A maioria dos respondentes coloca na conta das ferramentas essa preocupação, acreditando que são elas que deveriam se responsabilizar por seguir as normas regulatórias e termos de serviço da própria plataforma. Assim como (eu acredito que) no Brasil, alguns profissionais reconhecem que isso é algo no qual precisam trabalhar, mas possuem limitações de orçamento e tempo para lidar da forma correta – tanto do ponto de vista ético quanto legal, é bom diferenciar.
DESENVOLVENDO PROCESSOS E METODOLOGIAS PARA SOCIAL LISTENING
O terceiro capítulo é um dos mais interessantes, pois apresenta os “casos de uso” mais comuns do social listening. Esta talvez seja uma das maiores dificuldades que ferramentas e profissionais – também aqui no Brasil – possuem no sentido de resumir para que o listening serve, o que ajudaria muito a consolidar melhor a prática. No relatório, por exemplo, alguns desses objetivos/casos são mais amplos (posicionamento e estratégia de marca), outros mais específicos (monitoramento de saúde da marca).
Ainda que essa falta de direcionamento complique um pouco, identifiquei cada objetivo em torno de quatro grandes pilares: branding, indústria, consumidor e mensuração. Em branding estaria o mais comum, desde a famosa saúde da marca, passando por gestão de crise até identificação de temas/influenciadores; em indústria, são objetivos mais amplos, possivelmente de negócios; consumidor seria pensando naquele que é diferente do usuário; e, mensuração, a parte de performance/métricas.
QUAIS SÃO OS SEUS OBJETIVOS PRIMÁRIOS AO ANALISAR DADOS DE MÍDIAS SOCIAIS?
Posicionamento e estratégia de marca 51% [BRANDING]
Atitudes e opiniões 47.7% [BRANDING]
Inteligência competitiva 43.9% [MENSURAÇÃO]
Monitoramento de saúde da marca 39.4% [BRANDING]
Identificação de tendências dos consumidores 32.9% [INDÚSTRIA]
Desenvolvimento de serviço ou produto 29.7% [INDÚSTRIA]
Experiência ou jornada do consumidor 27.7% [CONSUMIDOR]
Relatório de marca 26.5% [BRANDING]
Interesses e afinidades do consumidor 25.8% [CONSUMIDOR]
Satisfação ou lealdade de clientes 24.5% [CONSUMIDOR]
Posicionamento e estratégia de marketing 18.1% [BRANDING]
Segmentação, tamanho e oportunidades de mercado 16.1% [INDÚSTRIA]
Gerenciamento de crise 16.1% [BRANDING]
Comportamento de compra do consumidor 14.2% [CONSUMIDOR]
Pesquisa de publicidade ou de mídia 13.5% [MENSURAÇÃO]
Mensuração de performance de conteúdo de mídias sociais 12.9% [MENSURAÇÃO]
Mensuração de performance de campanhas 11.6% [MENSURAÇÃO]
Seleção de temas e tópicos de conteúdo 9.7% [BRANDING]
Seleção de influenciadores 9% [BRANDING]
Objetivos mais comuns por “disciplina”
A quebra por “disciplina” (talvez departamento seria uma palavra mais apropriada) foi feita em dois momentos: para mostrar os objetivos mais comuns e a periodicidade das entregas. No primeiro caso, o destaque está nos outliers: desenvolvimento de produto/serviço aparece apenas em Brand e Data & Analytics; enquanto identificação de tendências dos consumidores aparece apenas em Research & Insight e Social Listening/Intelligence; já gerenciamento de crise só aparece em Brand e CX.
Essa quebra também revelou que todas as “disciplinas” possuem projetos ad-hoc como mais comum (exceto Data & Analytics), seguido de relatoria frequente a longo prazo. Mais uma vez, essa predominância de projetos ad-hoc (pontuais) talvez seja um sinal do perfil dos respondentes, visto que o mais comum no Brasil é, independente do departamento, a relatoria constante. Ainda assim, é difícil de ter essa visão geral pois a quebra por agência/marca também pode afetar nessas realidades.
Atividades nas quais gastam mais tempo
Outro ponto levantado nesta seção diz respeito ao processo de listening enquanto metodologia. Sobre isso, um dos respondentes cirurgicamente respondeu: “alinhar objetivos com o cliente, rodar a query [de busca] preliminar, revisar posts, revisar query se necessário, ler posts, categorizar posts, analisar dados categorizados, desenvolver uma narrativa, relatar e apresentar”. Aqui, assim como na respostas do gráfico sobre tempo por atividade, ficar mais uma vez evidente o perfil de pesquisa dos respondentes.
O relatório chama a atenção para a importância – o que eu concordo – em ter o maior tempo gasto alinhando com os clientes quais são as perguntas e problemas a serem endereçadas “para garantir que as perguntas sendo feitas são as certas e os objetivos dos projetos são claros”. Entretanto, pontua também a ausência de respostas de tempo investido na limpeza dos dados nessa etapa de planejamento, visto que a qualidade dos dados foi destaque como um dos principais desafios.
Ainda nessa temática, um resultado surpreendente da pesquisa é a constatação de que 53% dos respondentes relataram que ou quase sempre ou constantemente têm que analisar os dados fora das ferramentas de social listening (exportando). Os motivos para isso são vários: problemas com a taxonomia e categorização nas ferramentas, análises imprecisas e até querer juntar dados de mídias sociais com outras fontes de dados: “É mais fácil de manejar os dados no Excel”.
QUAIS SÃO OS PRINCIPAIS DESAFIOS EM ANALISAR DADOS DE MÍDIAS SOCIAIS PARA ENTREGAR INSIGHTS POR TODA A SUA ORGANIZAÇÃO?
Tempo e recursos limitados: “Enquanto softwares e ferramentas podem auxiliar na filtragem, nós investimos tempo em ler, agrupar e categorizar os resultados”.
Mostrar valor para outros departamentos e explicar as possibilidades do listening: “Muitas pessoas acreditam que social listening = análise de sentimento. Há tão mais que pode ser alcançado com dados de mídias sociais e demanda tempo e esforço para mudar esse pensamento”.
Funcionalidade limitada das ferramentas, principalmente quanto à necessidade de uma análise humana: “Nós reportamos sentimentalização mensalmente e por mais que o nível de acurácia aumente todo mês, eu ainda gasto muitas horas revisando.”
COMPREENDENDO A CULTURA ORGANIZACIONAL EM TORNO DO SOCIAL LISTENING
O quarto e último capítulo do relatório aborda questões sobre o social listening possivelmente como “disciplina separada” – realidade que, segunda a pesquisa, tem aumentado em empresas enterprise – e a sua relação com os demais departamentos de uma empresa. Essa mudança na estrutura das organizações – de pequenas atividades descoordenadas (em 2019) para departamentos centralizados em alinhamento com outras áreas de negócio – foi registrada tanto para marcas quanto para agências.
O tamanho dessas equipes varia entre 2 a 4 pessoas (segundo 35,5% dos respondentes) até times com mais de 8 profissionais (segundo 34,4% dos respondentes): “no entanto, ao observarmos a diferença entre marcas e agências […], percebemos que marcas são mais propensas a terem times menores”. 48% dos times de marcas registraram um tamanho de 2 a 4 pessoas, contra 27% dos times de agência. 21% dos times de marcas registraram times com mais de 8 pessoas, contra 43% de agências.
Essa diferença se evidencia também nos propósitos: enquanto profissionais que trabalham em marca focam em fornecer insights para clientes internos (85,5%) e fornecer acesso a dados e dashboards (63%), respondentes que trabalham em agências registaram a consultoria de insights estratégicos (67%) como a principal atividade. As áreas ou departamentos a quem os times de listening fornecem seu trabalho são: customer insights (77%), trends (65%) e inteligência competitiva (62%).
QUAL FOI O IMPACTO DA COVID-19 NO SOCIAL LISTENING?
58% das marcas estão usando MAIS dados de mídias sociais desde o início da pandemia;
50% das agências estão usando MAIS dados de mídias sociais desde o início da pandemia;
13% das agências agora recebem MAIS atenção no modo como usam dados de mídias sociais;
10% das marcas agora recebem MAIS atenção no modo como usam dados de mídias sociais.
O final desta seção ainda traz algumas questões (e respostas) bem interessantes sobre como o social listening é visto por outras áreas/departamentos de uma empresa. Na pesquisa, apenas 34% dos respondentes acreditam que seus colegas compreendem o que eles fazem, enquanto 61% acredita que eles apenas compreendem parcialmente. Além disso, 29% acredita que o listening é visto como parte integral do negócio – maior em agências (39%) do que em marcas (14,5%).
Quais são os principais desafios para a sua organização em termos de destravar o poder da análise de dados de mídias sociais para gerar tomada de decisões?
Orçamento, falta de integração com outras fontes de dados, lacuna de habilidades e incapacidade de mostrar ROI foram os principais desafios tanto para agências quanto para marcas. Já falta de visão ampla organizacional para o listening, dependência exagerada em pesquisa de mercado tradicional, falta de alinhamento entre esforços do negócio e falta de compreensão de tomadores de decisão sêniors foram os destaques para marcas. Em agências, problemas de privacidade, segurança e compliance.
AOS FINALMENTES
O relatório encerra com quatro principais descobertas/recomendações: 1) é imprescindível a elaboração de boas práticas padronizadas para o mercado; 2) profissionais precisam entender o papel da tecnologia quando se trata de garantir a qualidade e a segurança dos dados; 3) ainda não sabemos com certeza o impacto que o social listening possui sobre os negócios porque falta um feedback consolidado e; 4) profissionais de social listening são responsáveis por mostrar o valor da inteligência com dados de mídias sociais (mesmo sabendo que listening não responde a todos os problemas de negócio).
Apesar das evidentes diferenças com o mercado brasileiro (principalmente no que diz respeito ao perfil dos respondentes), acredito que esses quatro pontos se encaixam quase que perfeitamente à nossa realidade. Lá fora, o próprio SI LAB pode auxiliar no primeiro ponto, pois só na troca entre profissionais é possível desenvolver essas boas práticas. O segundo ponto só vem também com mais discussão de todas as partes envolvidas, marcas, agências e ferramentas. O terceiro é uma dificuldade que a própria pesquisa já enfrenta, e um quarto é a conclusão de todos os outros.
No prefácio do livro “Análise de Redes para Mídia Social” (2015), o sociólogo Marc A. Smith introduz a obra de Raquel Recuero, Marco Bastos e Gabriela Zago dando destaque sobretudo à emergência do aparato teórico-metodológico que permitiu a popularização dos estudos de redes a partir de dados da internet. “Enquanto nossa sociedade adota a mídia social como um novo fórum para o discurso público, criando uma praça pública virtual, há uma necessidade crescente de ferramentas e métodos que possam documentar esses espaços […]”, explica.
A mídia social pode ser um fluxo desconcertante de comentários, uma assustadora mangueira de incêndio esperramando conteúdo. Com melhores ferramentas e um pequeno conjunto de conceitos da ciência social, o enxame de comentários, favoritos, etiquetas, curtidas, avaliações, atualizações e links pode revelar pessoas-chave, tópicos e subcomunidades. Quanto mais interações sociais moverem-se para grupos de dados que podem ser lidos por máquinas, mais novas ilustrações das relações humanas e organizacionais se tornam possíveis. Mas novos formatos de dados requerem novas ferramentas para coletar, analisar e comunicar percepções.
SMITH, p. 11.
Seis anos antes, a própria Recuero já chamava a atenção em “Redes Sociais na Internet” (2009) para como a (popularização e consolidação da) interação mediada por computador facilitou a produção de rastros identificáveis, a difusão de conteúdos diversos e a ampliação de limites interacionais. Esses aspectos foram desenvolvidos com mais detalhes em outra obra de sua autoria, “A conversação em Rede: comunicação mediada pelo computador” (2014), agora em torno da caracterização de elementos e dinâmicas especificamente dos sites de redes sociais (SRSs).
As affordances propostas por danah boyd para pensar os públicos em rede (networked publics) – persistência, replicabilidade, escalabilidade e buscabilidade – ratificam como a internet (ou os SRSs) se tornou(aram) um espaço prolífero para identificar as “novas” formas de sociabilidade das últimas décadas. Nas palavras de Richard Rogers em “The End of the Virtual” (2009): “A questão não é mais saber o quanto da sociedade e da cultura está online, mas sim como diagnosticar mudanças culturais e condições da sociedade através da internet”.
Cerca de dez anos já se passaram desde a publicação dessas obras mais antigas e muitas outras questões (inclusive problemáticas) já entraram em cena, mas o interesse em fazer pesquisa com dados de mídias sociais segue crescente. A grande área da Comunicação (incluindo aqui também os chamados Media Studies), provavelmente a primeira que se propôs a avançar as discussões e as metodologias desse novo ecossistema social, hoje já partilha desse interesse com outras disciplinas das Ciências Humanas e o restante das Ciências Sociais Aplicadas.
É nesse contexto que surgem (sub)disciplinas/campos como as Humanidades Digitais (Sociologia Digital, História Digital), que unem as epistemologias específicas das Ciências Humanas com muito do que foi desenvolvido sobre mídias digitais nas últimas décadas (que localizo em Comunicação, mas cujos fundamentos são também muito ligados à Sociologia, por exemplo). Acrescentamos a esse cenário as técnicas de coleta/tratamento/análise de dados de áreas ainda mais distantes, como a Ciência da Computação ou Engenharia da Informação.
Pessoas de várias disciplinas são atraídas para o estudo da internet por muitas razões. Alguns querem utilizar as tecnologias para conduzir pesquisa tradicional dentro de suas bases disciplinares, outros querem se libertar dos grilhões das práticas disciplinares tradicionais. Alguns querem compreender algo sobre tecnologias particulares, mas possuem pouco treinamento em métodos para estudá-las. Outros sabem muito sobre os métodos da pesquisa sociais mas pouco a respeito do contexto tecnologicamente mediado que eles estão estudando.
(MARKHAM e BOYD, 2009, p. XIII apud FRAGOSO et. al, p. 28-29)
O que temos hoje, portanto, é um cenário de fartura de dados, ferramentas refinadas, metodologias consolidadas e avanços teórico-epistemológicos interdisciplinares. Em outras palavras: todo mundo quer um pedacinho desse bolo multicamadas. Este post, portanto, é para você que está na graduação ou numa pós e está doido para provar o sabor dessa belezura, mas que não faz ideia por onde começar – ou nem tem certeza se é realmente esse bolo que vai alimentar a sua fome (pode até achar que sim, mas talvez – mais para frente – descubra que não).
Neste post, pretendo apresentar aqui algumas orientações/indicações do que eu acredito que pode vir a ser útil para a sua jornada enquanto pesquisador acadêmico que deseja/pretende trabalhar com dados (publicações, principalmente) de mídias sociais. Já deixo aqui o agradecimento à minha amiga Aianne Amado, que tem desenvolvido comigo alguns projetos que passam por essa temática; e ao mestre (e meu ex-chefe) Tarcízio Silva, que me apresentou a maioria dessas discussões, autores e, principalmente, ferramentas e metodologias.
A proposta aqui não é a de oferecer um panorama geral, que exigiria uma elaboração ainda mais cuidadosa e “cientificamente responsável” (como em uma revisão bibliográfica ou estado da arte), mas apontar alguns caminhos interessantes para esse trabalho. Já são mais de duas décadas de produção acadêmica tanto no Brasil quanto lá fora que pavimentaram o chão no qual podemos caminhar hoje em dia, então é importante conhecer alguns desses esforços para continuarmos trilhando essa jornada sem querer reinventar a roda.
Apontamentos iniciais para a pesquisa acadêmica com dados de mídias sociais
A primeira coisa que eu acho importante de fazermos (coletivamente enquanto comunidade acadêmica) é acalmar os ânimos. Com esse boom de dados que é explorado em diversas narrativas mercadológicas (big data, data scientist, etc.), acabamos querendo também entrar nessa onda apenas para, como falei na metáfora anteriormente, pegar um pedacinho desse bolo. Vale, então, perguntar-se: será que o meu interesse de pesquisa se encaixa nesse contexto e/ou pode ser respondido a partir de dados (publicações) de mídias sociais?
Começo, portanto, apresentando quatro pontos que acredito que precisamos levar em consideração ao nos propormos a realizar pesquisa em mídias sociais. São questões que trago não para esgotarmos as discussões (que são complexas e podem ter argumentos consideralmente conflitantes) ou para desestimular o interesse por essa jornada, mas para pensarmos também o que não pode ser pesquisado a partir desses dados – ou até pode, mas que precisa ser responsavelmente abordado na teoria e metodologia da pesquisa.
1. Não pule para a metodologia antes de definir o objetivo e o problema de pesquisa
Na abertura do livro “Methods of Discovery: Heuristics for the Social Sciences” (2004), o sociólogo Andrew Abbott coloca que: “The heart of good work is a puzzle and an idea” (algo como “O coração de um bom trabalho [de pesquisa] é um quebra-cabeças e uma ideia”, em tradução literal). O autor chama a atenção para como o rigor e a criatividade devem andar lado a lado no fazer científico, para que seja possível destravar as ideias mais criativas através de métodos que devem servir de apoio, mas raramente de guias definitivos.
Trago essa referência porque muitas vezes o que eu vejo são estudantes de graduação ou pesquisadores de pós querendo utilizar certas metodologias apenas pela metodologia. Será que analisar tweets realmente responde à sua questão de pesquisa? Será que o que as pessoas publicam no Instagram se enquadra nas informações que você precisa para avaliar as suas hipóteses? Grafos são realmente muito bonitos (tenho uma amiga que sempre fala que parecem galáxias), mas será que eles atendem as suas necessidades?
2. Lembre-se que o Brasil ainda é um país extremamente desigual
Ainda nessa questão de êxtase por dados, não se engane: o Brasil infelizmente – e com índices piorados devido à pandemia e o descaso do governo federal – continua sendo um país com diversos problemas socioeconômicos. A pesquisa TIC Domicílios 2019 realizada pelo Centro Regional para o Desenvolvimento de Estudos sobre a Sociedade da Informação (Cetic.br) indicou que 80% dos brasileiros possuem acesso à internet, mas há diferenças importantes para serem consideradas a partir de recortes de renda, gênero, raça e regiões.
Gráfico desenvolvido pelo Canal Tech a partir do relatório da Cetic.br
Não se engane (como propõe o mercado de marketing/publicidade): pesquisas e relatórios de institutos como o próprio Cetic.br ou o IBGE, por exemplo, são bem mais importantes do que estudos de agências cool sobre a mais nova tendência digital para dois mil e tanto. Essa ponderação retorna ao primeiro ponto levantado: será que o que é produzido pelos pessoas na internet – às vezes, mais especificamente, nas mídias sociais – realmente atende o que você necessita? São 1) brasileiros falando sobre ou 2) “internautas” brasileiros falando sobre?
3. Entenda muito bem como os usuários se apropriam de cada plataforma e quais dados (conteúdos) geram em cada uma delas
Este ponto parte de dois lugares diferentes, mas com o mesmo pressuposto: a facilidade de falar de mídias sociais (ou sites de redes sociais) como um grupo. Quando falamos em fazer pesquisa sobre/nas/com dados de mídias sociais, estamos supondo que se trata de um coletivo relativamente homogêneo, semelhante – o que não necessariamente é o caso para todas. Embora autoras como danah boyd e Nicolle Ellison tenha, em 2007, tentando propor algumas características em comum para esses sites, mais de 10 anos depois, esse conceito se complexificou muito.
O problema, portanto, encontra-se neste lugar que pressupõe uma classificação bem definida para mídias sociais (ou sites de redes sociais), mas não leva em consideração como suas próprias arquiteturas estão em constante atualização, complicando suas semelhanças e diferenças. E aí entra outra questão também muito importante: o modo como as pessoas se apropriam e fazem a utilização de cada plataforma. Cada espaço estimula produções diferentes de nós mesmos, atendendo ainda à maquinaria da opinião pública – que une pessoas, empresas, personalidades, etc.
Em outras palavras, o que você publica/compartilha no Facebook não é a mesma coisa que você compartilha no Instagram, LinkedIn ou Twitter. Os públicos com os quais você interage em cada um desses sites (familiares, grupos de amigos, conhecidos, contatinhos, etc.) é muito provavelmente diferente, e isso tanto implica quanto está implicado no tipo de conteúdo que será gerado em cada um deles. Se você consegue perceber isso da perspectiva de usuário, deve também ter isso em mente enquanto pesquisador/a.
4. Fique por dentro das discussões sobre algoritmos, inteligência artificial, etc.
Além de nos comportarmos de modos diferentes em cada uma das plataformas (geralmente de acordo com as audiências às quais nos apresentamos), também somos moldados – ou melhor, moldamos nossas conversas – de acordo com o que está sendo falado, apresentado, compartilhado e/ou debatido em cada uma delas. Acontece que, infelizmente, esse processo de pauta envolve atores que atrapalham/complexificam a “espontaneidade” das conversas: empresas, marcas e as próprias mídias sociais – que possuem um modelo de negócio estruturado para isso.
Muito tem sido discutido – principalmente na academia – sobre as bolhas das mídias sociais, câmaras de eco, viés algorítmico, (des)inteligência artificial e assuntos correlatos. Embora cada temática e cada pesquisa aborde essas problemáticas a partir de uma discussão própria, acredito que o que todas elas possuem em comum é a constatação de que precisamos problematizar (e responsabilizar) as políticas de negócios das big techs, visto que todas as suas tomadas de decisões têm impacto e são impactadas pelo modo como as pessoas utilizam seus serviços.
Da cibercultura à era pós-APIs: um panorama não-oficial dos estudos da internet e das mídias sociais (no Brasil)
Talvez não esteja tão evidente assim, mas o principal intuito deste texto é apresentar algumas ferramentas e técnicas para a coleta/extração e análise de dados de mídias sociais. Para chegar aí, entretanto, estou tentando apresentar várias questões que considero importantes para pesquisadores que pretendem trabalhar com isso. Além dos apontamentos iniciais já apresentados, percebo também a necessidade de explicar onde estamos atualmente. Ou melhor: de onde vimos, como chegamos até aqui e (possivelmente) para onde vamos?
Como tenho tentado enfatizar durante todo o texto, fazer pesquisa sobre a internet, na internet ou com dados da internet não é algo nada novo. O que se proliferou consideravelmente na última década, porém, foi tanto a produção desenfreada de dados aos montes (em todos os aspectos da nossa vida) quanto as possibilidades de obtenção desses dados por diferentes atores e através de diversas capacidades técnicas (para o “bem” e para o “mal”). Como, então, podemos fazer o entendimento desse processo – e por que é tão importante fazê-lo?
No capítulo “Panorama dos Estudos de Internet” do livro “Métodos de pesquisa para internet” (2011), Fragoso, Recuero e Amaral fazem um compilado do que, até então, estava à frente dessa temática. Apresentam a proposta de pensar “os estudos de internet como um campo em constante mudança (Jones, 1999) surgido a partir de diversas disciplinas (Baym, 2005) […] dentro de um contexto sócio-histórico que dialoga com a tradição dos estudos de comunicação, cultura, mídia e tecnologia (Sterne, 1999)”.
Fases dos Estudos sobre Internet
1a Fase (Início dos 90)
2a Fase (Segunda metade dos 90)
3a Fase (Início dos 00)
Wellmann (2004)
Dicotomia entre utópicos e distópicos; a narrativa da história da comunicação parece ter início com a internet.
Inicia por volta de 1998; coleta e análise de dados: documentação e observação sobre os usuários e suas práticas sociais; internet começa a atingir um público maior e mais diverso do que o da fase anterior; pesquisa de opinão e entrevistas; resultados atingidos: apropriações feitas por diferentes classes sociais, gêneros, faixas etárias etc.
Abordagem teórico-metodológica: enfoque na análise dos dados; reflexões sobre padrões de conexões, personalização e comunicação.
Postill (2010)
Hype acerca do próprio surgimento da internet; polarização real versus virtual; internet como esfera autônoma; interações síncronas versus assíncronas.
Análise do objeto internet já inserida dentro do cotidiano; comparações entre a internet e outras mídias; popularização da internet para vários tipos de usuários; amostragem intencional (escolha de casos extremos)
Enfoque nos usos e apropriações; explicitação metodológica.
Observações
Para Postill, sobretudo nas duas primeiras fases, há muita ênfase no hype sobre a própria internet.
Wellmann indica uma predominância na segunda fase dos estudos quantitativos, enquanto que na segunda fase a abordagem qualiquantitativa tem aparecido com mais força.
Tabela 1: Principais fases dos estudos de internet para Wellmann (2004) e Postill (2010).
Na Tabela 1, que reproduzo acima, apontam as fases dos estudos sobre internet a partir de dois autores, elaborando o argumento de se pensá-la não como disciplina, mas como um campo. Chamam a atenção, entretanto, para como essa historicização “merece ser relativizada, no sentido que, corresponde, em grande parte, ao desenvolvimento das pesquisas no contexto anglo-saxão”. No Brasil, apontam que “um direcionamento rumo a pesquisa empírica em internet entra com maior força apenas a partir da segunda metade dos anos 2000”.
Acrescentam que “antes disso [da segunda metade da década], boa parte dos estudos voltava-se a aspectos filosóficos ou até mesmo psicológicos cujas abordagens eram estritamente teóricas e e/ou ensaísticas sem comprometimento com coleta de dados no campo“. Esses estudos, no contexto brasileiro das Ciências Humanas e das Ciências Sociais Aplicadas, encontravam-se sobretudo associado aos estudos de cibercultura e dos estudos de interface humano computador (IHC). Surge, então, a pergunta: o que mudou a partir de 2005 em diante?
Eu fiz essa linha do tempo para apresentar em duas oportunidades que tive de falar com alunos, professores e pesquisadores acadêmicos sobre coleta de dados em mídias sociais (e como chegamos na era pós-APIs). Selecionei algumas obras não necessariamente por relevância ou impacto teórico (no Brasil e à fora), mas para tentar explicar mais ou menos o que aconteceu – a partir da minha interpretação – na primeira década do milênio em termos de internet, sites de redes sociais e, consequentemente, pesquisas que os envolvem de alguma forma.
No início dos anos 2000, as pesquisas e estudos de internet eram muito voltados para uma perspectiva mais sociotécnica – e que vislumbrava várias abordagens, das mais pragmática às mais distópicas/utópicas. Era também o momento em que a World Wide Web se consolidava como uma das grandes “revoluções” do mundo moderno, com várias expectativas realmente revolucionárias do que poderia estar por vir. Havia um entusiasmo muito grande com a possibilidade de conexão e descentralização dos meios de informação/comunicação.
Outra proposta de reflexões teóricas sobre a cibercultura (SCOLARI, 2009)
Acho importante também abrir um parênteses para falar do fenômeno da web 2.0, hoje até negligenciado, principalmente em termos de discussão, mas que foi fundamental para a consolidação do que temos atualmente. No início da internet, eram pouquíssimas as pessoas que podiam produzir conteúdo: a web 1.0 era formada por webmasters que sabiam fazer sites (HTML) completamente estáticos e usuários que navegavam por esse espaço; na web 2.0, esse cenário se torna mais dinâmico com a introdução de possibilidades com XML e RSS (de onde nascem os blogs, wikis, etc.).
Em meados dos anos 2000, “entrar” na internet já era algo bastante comum para boa parte da população brasileira. Foi o período de febre das lan houses, dos joguinhos online, da evolução dos discadores para banda largas, etc. – e também o primeiro momento em que um site de rede social ganha força: o Orkut. A meu ver, nessa época, a discussão virtual x offline (herança da década de 90) ainda continuava com bastante força, com muito sendo discutido – inclusive na imprensa – sobre comunidades virtuais, subculturas virtuais e mundos virtuais (Second Life, Habbo Hotel, etc.).
Duas coisas acontecem no final dessa década que, a meu ver, são fundamentais para o que viria a seguir – e estão bastante interligadas: a popularização de smartphones (e, obviamente, a ascensão econômica dos brasileiros para adquirirem esses objetos) e a consolidação da internet móvel (3G). Esse cenário foi fundamental para que, no final dos anos 2000, sites de redes sociais como Facebook, Twitter e YouTube ganhassem a projeção social e econômica que têm hoje em dia. Paramos de “entrar” na internet, que se tornou embutida, incorporada e cotidiana (HINE, 2015).
É também nesse contexto que a World Wide Web, que nasce com um entusiamo de revolução, é cooptada pelas garras do capitalismo nos modelos de negócios desenvolvidos pelas empresas de mídias sociais. Internet vira, de certo modo, sinônimo de redes sociais – um ponto obrigatório de passagem. Da Tabela 2, que também reproduzo do livro de Fragoso et. al, percebemos um redirecionamento dos estudos de internet em termos de abordagem teórica, cada vez mais em direção a pensá-la como artefato cultural e/ou como mídia mesmo.
Abordagem Teórica
Internet como Cultura
Internet como Artefato Cultural
Internet como Mídia
Conceitos
Ciberespaço, vida virtual, cibercultura, descorporificação, desterritorialização.
Online/Offline, incorporada à vida cotidiana, localidade.
Convergência de mídia, vida cotidiana, novas mídias, cultura digital.
Objeto/Campo
Com base no texto: Chats, BBS, IRC, Usenet, Newsgroups, MUDs
Com base na web: Páginas pessoais, websites, mundos virtuais.
Redes sociais, objetos multimídia: Conteúdo gerado por consumidor, Web 2.0.
Metodologia Qualitativa Etnografia
Comunidades Virtuais, Comunicação Mediada por Computador, Identidade Online, Estudos feitos exclusivamente em tela.
Laços sociais, representação de identidade, “estudos além da tela”, apropriação da tecnologia, etnografia virtual.
Etnografia multimídia, etnografia conectiva, etnografia das redes.
Tabela 2: Abordagens teóricas sobre a internet enquanto objeto de estudo. Fonte: Ardevol et al. (2008)
Percebemos, portanto, que, a partir da virada da década, os sites de redes sociais (SRSs) passam a tomar conta, com várias das produções acadêmicas sendo principalmente dedicadas a esses fenômenos. O projeto de pesquisa “Why We Post”, liderado pelo etnógrafo Daniel Miller na University College London busca, desde 2012, compreender os usos e as consequências das mídias sociais no mundo inteiro. No Brasil, temos também a tese “Dinâmicas identitárias em sites de redes sociais” (2014), de Beatriz Polivanov, que vira livro e referência na área.
Essas obras não necessariamente trazem novos paradigmas para o campo da pesquisa na internet, mas atualizam e referenciam muito – o trabalho de Polivanov, por exemplo, traz bastante da produção brasileira das próprias autoras Raquel Recuero, Adriana Amaral, Suely Fragoso, Sandra Montardo, etc. – dos métodos já populares, como (n)etnografia virtual, entrevista em profundidade, etc. No entanto, dando continuidade à promessa da web 2.0, a produção de conteúdo gerado por usuários exige que essas pesquisas também atualizem seus repertórios ferramentais.
Nesse contexto, grupos como o Digital Methods Initiative da Universidade de Amsterdã surgem com alternativas para explorar dados da internet – e, consequentemente, dos sites de redes sociais – em grande escala. O livro “Digital Methods” (2013), de Richard Rogers, líder do grupo, é a publicação que reafirma a iniciativa de estruturar ferramentas capazes de compreender a sociedade através da internet, principalmente sob a perspectiva de redes, rastros de conflito, arquivos de conteúdo, etc. – para estudar cliques, hiperlinks, curtidas, comentários, etc.
Várias outras publicações também surgem nesse mesmo momento com o intuito de pensar métodos para fazer pesquisas com/nas mídias sociais, mas aqui chamo a atenção para essa produção do DMI devido à proposta do grupo de produzir principalmente um aparato técnico que desse conta desse novo cenário. E se hoje estamos vivendo a era da pesquisa “pós-APIs”, é porque foi nesse momento – e também com a ajuda de projetos como esse, muito ancorados nas lógicas das APIs – que a coleta de dados de mídias sociais pôde se popularizar tanto.
Para explicar isso, vou ter que voltar um pouquinho na nossa historicização da web. Quando os sites de redes sociais surgiram, eles eram também fruto da lógica da web 2.0 (que, como expliquei, teve como primeiros produtos os blogs e wikis, mas cuja evolução disso fica evidente na proposta das mídias sociais). Essa lógica da cultura colaborativa trazia consigo um estímulo de co-desenvolvimento para que as pessoas também pudessem criar e elaborar projetos em cima de estruturas e códigos já previamente estabelecidos (que é a cultura da programação até hoje).
As APIs (Application Programing Interface), que são basicamente “séries de comandos que permitem a usuários e aplicativos se comunicarem com os sites e requisitarem dados hospedados em seus servidores” (ALVES, 2017, p. 2016), foram lançadas praticamente junto às próprias mídias sociais. Foram a partir delas que vários aplicativos ganharam também bastante popularidade – como aqueles joguinhos do Facebook de meados de 2010 (Farmville, Colheita Feliz, SongPop), ou o antigo Twitpic de quando o Twitter ainda não permitia publicar imagens.
Foi a partir dessa oportunidade que muitos dos softwares acadêmicos desenvolvidos no final da primeira década dos anos 2000 e início da década seguinte ganharam também muita força, sendo talvez a Netvizz (do DMI), que permitia coletar dados do Facebook, a grande protagonista de toda essa história. Infelizmente, não por um bom motivo: quando os problemas começaram a vir à tona, a ferramenta foi aos poucos enfrentando limitações cada vez mais severas. O próprio Rogers, que ajudou a popularizar as ferramentas do seu grupo, foi forçado a admitir:
Ao construir as infraestruturas necessárias para apoiar e rastrear a crescente quantidade de interações online e ao tornar os registros resultantes disponíveis através das APIs, as plataformas reduziram significativamente os custos dos dados de mídias sociais. A facilidade da pesquisa com APIs veio com o preço de aceitar a padronização particular operada pelas plataformas de mídias sociais e o enviesamento que vem junto. […] Num frenesi consumista, nós estocamos dados como commodities produzidas em massa. A pesquisa com APIs é culpada (pelo menos em parte) por espalhar o hype dos dados de mídias sociais, reduzindo a diversidade de métodos digitais ao estudo de plataformas online, e por espalhar as ideias pré-concebidas de que o Facebook, o Google, o Twitter e seus semelhantes são os mestres do debate online, e não há alternativas a não ser viver sob as migalhas de suas APIs.
(VENTURINI, ROGERS; 2019)
A “era das APIs” realmente facilitou muito uma das etapas do processo metodológico de pesquisa com dados de mídias sociais, a coleta/extração dos dados, mas a verdade é que muita pesquisa já foi feita – inclusive no mesmo período – sobre mídias sociais sem necessariamente depender dessa alternativa. O próprio termo “pós-APIs” parece, hoje, demasiadamente apocalíptico, visto que várias plataformas continuam com APIs ainda bastante favoráveis principalmente àqueles interessados a realizar pesquisa acadêmica com dados de mídias sociais.
O Twitter lançou recentemente uma versão de sua API exclusiva para acadêmicos com acesso inédito a um volume de dados jamais visto até em algumas das suas opções pagas. O YouTube continua com a API funcionando relativamente bem, com ferramentas como o YouTube Data Tools (DMI) ainda no ar. Até mesmo o Facebook, maior site de rede social da atualidade, que começou a fechar sua API em 2015 e depois do seu afiliado Instagram em 2016, hoje tem a CrowdTangle como alternativa oficial da empresa para pesquisadores acadêmicos.
Ainda temos um cenário bastante próspero para quem deseja trabalhar com coleta de dados de mídias sociais, embora os tropeços dos últimos ainda. É importante, entretanto, ter em vista que “muitos dados” não é necessariamente o equivalente a uma pesquisa melhor, mais válida ou mais rica. Essa perspectiva positivista pela evidência quantitativa eufórica não é o legado que duas décadas de estudos de internet nos deixa, com um vasto repertório de métodos qualitativos sendo explorados, discutidos e potencializados no Brasil e à fora.
Abordagens e ferramentas de coleta para mídias sociais – quais dados estão disponíveis?
Há basicamente três maneiras para se coletar dados de mídias sociais (em 2021): via APIs, raspagem de dados (web scraping) ou manualmente. Qual é a diferença entre cada um deles e o que isso implica? Antes de responder essa pergunta, preciso admitir uma coisa: quando estou falando aqui de “dados de mídias sociais”, estou me referindo principalmente às publicações que são feitas pelos usuários (o famoso UGC – user-generated content) e/ou às informações semipúblicas disponíveis a nível de usabilidade das plataformas (seguidores, por exemplo).
No entanto, é evidente que os dados que geramos nas mídias sociais correspondem a muito mais do que isso. Cliques, alcance, tempo em tela, taxa de rejeição (bounce rate), dentre várias outras métricas também podem ser consideradas para análise de mídias sociais. No mercado de comunicação digital, essa diferença se estabelece nas definições de monitoramento e métricas, em que a segunda está muito mais associada a dados fornecidos pelas próprias plataformas cujo foco está na mensuração para otimização de objetivos de negócios (venda, awereness, etc.).
O foco das pesquisas com dados de mídias sociais, portanto, costuma ser as conversações em rede – ou seja, o conteúdo (das mensagens ou dos perfis) ou as próprias interações. É por isso que a análise de redes se popularizou tanto nas últimas décadas, por fornecer o aparato técnico-metodológico (e teórico) para compreendermos principalmente a lógica de conexões das redes – que estão nas trocas de mensagens, mas também na associação entre os atores (amizade, seguidores, vídeos relacionados, etc.), disseminação de (des)informação, etc.
Para gerar essas redes com centenas, milhares, às vezes milhões de conexões, alternativas de coleta via API ou web scraping facilitam muito o processo – o que não quer dizer que uma rede não possa também ser produzida manualmente. O mesmo vale para a análise de conversação/conteúdo, que também ganhou bastante notoriedade nas produções acadêmicas da última década. Na tabela abaixo, apresento de modo bastante simplificado/didático quais são as principais diferenças entre essas três opções de coleta, já listando algumas ferramentas.
APIs
Raspagem de dados (web scraping)
Coleta manual
Como utilizar?
– Ferramentas plenas comerciais – Softwares acadêmicos – Códigos e scripts de programação
– Códigos e scripts de programação
– Copia e cola – Captura de tela
Limitações e implicações
– Dados disponíveis de acordo com a documentação de cada plataforma
– Prática vai contra os Termos de Serviço das plataformas – Pode ter consequências operacionais e até jurídicas
– Assim como raspagem, envolve questões éticas da privacidade dos usuários
Exemplos de ferramentas ou softwares
– Netlytic, YouTube Data Tools, Facepager
– Twint, SNScrape, Instagram-Scraper
– Spreadsheets, Excel, LibreOffice
Fazer a extração/coleta de dados via API significa basicamente utilizar das portas de acesso que as próprias plataformas disponibilizam para terceiros terem acesso a seus dados. Essa prática diz respeito ao modo como a web, que surgiu otimista pela descentralização de acesso, tem se transformado cada vez mais em plataformas proprietárias de empresas – como no caso das mídias sociais. A plataformização da web diz respeito a um modelo econômico dominante e as consequências da expansão das plataformas de redes sociais em outros espaços online.
O pesquisador brasileiro Marcelo Alves traz esse argumento da pesquisadora Anne Helmond – integrante do Digital Methods Initiative (DMI) – em que explica que “as APIs permitem fluxos de dados cuidadosamente regulamentados entre plataformas sob a forma de APIs abertas ou APIs proprietárias”. Essas infraestruturas programáticas que definem barreiras e se comunicam com o restante da web por meio de aplicações direciona a política de fluxo de dados, nas quais os planos de negócio das empresas são representadas através de permissões e leis de acesso.
Gráfico do artigo “Is the Sample Good Enough? Comparing Data from Twitter’s Streaming API with Twitter’s Firehose” comparando a mesma coleta através de duas APIs do Twitter
Há, portanto, dois pontos importantes em relação às APIs: suas documentações e chaves de acesso (token). As primeiras geralmente são disponibilizadas publicamente nos sites das plataformas (com dicionários sobre pontos de exportação, informações para consultas, erros comuns, etc.), mas a segunda exige uma requisição a ser solicitada (para conseguir uma chave). São diversos níveis de autorização, acesso e proibições de pontos de dados, cuja diversidade dos metadados está de acordo com as permissões concebidas (ALVES, 2018).
Em termos práticos, portanto, é imprescindível que os pesquisadores interessados nos dados dessas plataformas entendam como ler a documentação fornecida e aprendam a operacionalizar as interfaces para tirar o máximo de proveito de acordo com seus objetivos. Isso implica, entretanto, ter o mínimo de conhecimento de programação para saber como fazer requisições aos servidores do Facebook, Twitter ou YouTube – o que dificulta um pouco esse processo, como também é o caso para a opção de raspagem de dados (scraping).
É por isso que várias ferramentas/softwares foram desenvolvidas na última década a partir de iniciativas como a DMI para facilitar o acesso de pesquisadores acadêmicos aos dados fornecidos via API. Já citei aqui algumas delas, como: a falecida Netvizz que permitia acesso a dados do Facebook; a Netlytic e sua irmã mais nova, Communalytic, desenvolvida por pesquisadores da Social Media Lab com funcionalidades robustas de análise (de redes, inclusive) a partir da coleta de dados do Twitter, YouTube, Facebook/Instagram; e a YouTube Data Tools.
Todas essas fazem (ou faziam, como no caso da Netvizz) uso das APIs das plataformas, o que pode ser um grande facilitador em vários sentidos. No entando, apesar dos benefícios de interfaces que não exigem conhecimento de programação e repositórios online independentes da nossa máquina pessoal, o maior problema delas também está no trunfo das APIs e suas limitações. A versão gratuita para desenvolvedores, do Twitter, por exemplo, até recentemente só permitia a coleta de alguns milhares de tweets a cada 15 minutos e com um retroativo de até, no máximo, 7 dias.
É nesse contratempo – de modo mais amplo – que surge a alternativa de raspagem de dados (ou scraping, em inglês), que nada mais é do que um procedimento automatizado de uma coleta que você também poderia fazer manualmente. Isso porque essa técnica geralmente extrai os dados a partir de uma linguagem de marcação (HTML) do seu código-fonte, na qual “o mecanismo exibe a página e procura na linguagem de marcação pelas partes específicas referentes aos dados que precisamos” (ALVES, 2018, p. 24).
A maior dificuldade de se trabalhar com web scraping é ter o mínimo de conhecimento de programação para saber como rodar scripts em Python e R. No entanto, trabalhar com APIs também exige um conhecimento de técnicas e linguagem de programação para poder fazer as requisições (e até mesmo ler as documentações de acesso). A boa notícia é que para ambos os casos há vários scripts – códigos escritos por programadores, desenvolvedores, etc. – disponibilizados publicamente em repositórios como o GitHub.
Para quem não quer utilizar as ferramentas acadêmicas já citadas (que podem custar caro no bolso brasileiro) para extração via API, há projetos como o Facepager e o Social Feed Manager que já fazem boa parte do trabalho de programação por você, sendo necessário apenas alguns ajustes de configuração do acesso. Já quem não possui boas chaves de API à disposição, alguns scripts de raspagem como o Twint, o Instagram-Scraper e o SNScrape podem ser interessantes. Acima, compartilho vídeos-tutoriais de como instalar o Python para utilizá-los.
Além de todas as opções, há três iniciativas que estão constantemente atualizando suas listas de ferramentas para pesquisa em mídias sociais: o Social Media Research Toolkit do Social Media Lab/Social Media Data (com uma catalogação detalhada de variáveis importantes), o wiki Social Media Data Collection Tools organizado pelo Deen Freelon; e as ferramentas do médialab Sciences Po. Em seu blog institucional, o pesquisador Wasim Ahmed também já fez levantamentos de ferramentas em 2015, 2017, 2019 e recentemente em 2021.
Na tentativa de agregar todas essas ferramentas levantadas por esses repositórios e também incluir outras opções interessantes – inclusive projetos brasileiros, como o LTweet do LABCOM da UFMA -, criei recentemente uma planilha (ainda em construção – interessados em colaborar podem entrar em contato comigo!) para compartilhamento dentre a comunicade de pesquisadores brasileiros. No final das contas, o que fica evidente é que opção não falta para conseguirmos algum jeito de coletar/extrair dados de mídias sociais – a escolha é sua.
Para continuar estudando: uma nota pessoal, referências e métodos/metodologias mais comuns
Tentei, ao longo deste post, construir a minha fala em cima de vários referenciais teóricos e uma perspectiva mais impessoal sobre o assunto. Gostaria de finalizá-lo, entretanto, carregando um pouco a mão no eutnocentrismo, começando pelos motivos que me fizeram escrevê-lo, que são três: um pedido de ajuda de uma mestranda da USP, uma fala para alunos da graduação do curso de Estudos de Mídia da UFF e uma oficina que ministrei junto à minha querida amiga Aianne Amado para graduandos, mestrandos, doutorandos e doutores da UFS/UnB.
Esses três eventos aconteceram (não simultaneamente) nos últimos dois meses e me fizeram não só refletir, mas levantar e preparar um material didático para esses três diferentes públicos que tinham o mesmo interesse: aprender como coletar e analisar dados de mídias sociais. Para cada um deles, eu tive que desenvolver um modo diferente de explicar tudo isso que falei aqui (nem com tanta profundidade ou entrando em tantos detalhes como fiz agora), levando em consideração o nível – e a formação – de conhecimento de cada um.
Escrevi este texto com o intuito de compilar tudo que pude passar nessas três ocasiões, agregando já as discussões que conseguimos propor em alguns deles, com o intuito principal de ser realmente um guia (introdutório) para quem deseja trabalhar com dados de mídias sociais. Há muito mais do que eu trouxe aqui, mas imagino (espero) que o que pude apontar – e questionar – sirva de contribuição para você, que está lendo até agora. A minha proposta nunca foi a de esgotar as possibilidades, mas abrir os horizontes para futuros navegantes.
Acho também importante colocar que embora a minha formação (graduação) seja em Estudos de Mídia/UFF, muito do que eu aprendi e conheci veio do meu trabalho no IBPAD, com a mentoria do meu mestre, Tarcízio Silva. Foi sob sua orientação que produzi o material “100 Fontes sobre Pesquisa e Monitoramento de Mídias Sociais”, com o qual descobri vários dos autores que citei; foi também onde aprendi a mexer na Netvizz, no YouTube Data Tools e no Netlytic; além da prática de análise de redes com o Gephi e, depois, com a WORDij.
No mestrado, optei por seguir para uma área interdisciplinar menos voltada para Comunicação, o que fez com que eu tivesse que estudar sobre métodos digitais por conta própria. É realmente muito desafiador se manter atualizado de todas essas discussões e dos próprios fenômenos digitais nesse campo em constante mudança que é a internet, mas tento acompanhar vários pesquisadores da área através do Twitter, para ficar de olho no que há de mais novo (no sentido de inovador mesmo) em termos de metodologias, ferramentas e técnicas.
No entanto, é importante que não nos deixemos cair no deslumbramento do que está no hype somente pelo hype (como fizeram os primeiros estudiosos de internet). É preciso olhar constantemente para trás – vide a tabela 3, do livro bastante citado aqui de Fragoso et. al (2011) – a fim de entendermos como conseguimos avançar sem necessariamente reinventar métodos já consolidados, mas pensar como podemos agregar novas metodologias aos cenários atuais e emergentes – como tem sido feito constantemente com as abordagens chamadas “métodos mistos”.
Objetos
Alguns métodos apresentados na literatura
Blogs Fotologs Videologs Moblogs Microblogs
Análise de conteúdo Análise de discurso Etnografia + ARS Entrevistas Estudo de caso Observação participante Método Biográfico Estatísticas
Páginas Pessoais Websites
Análise de Hyperlinks Etnografia Estudo de Caso Análise de webesfera Webometria
Portais
Estudo de caso – Método GJOL Etnografia Entrevistas em profundidade Análise documental
Pesquisa de opinião (survey) Observação Participante Entrevista Teoria Fundada
Sites de Redes Sociais
ARS Etnografia ARS + Etnografia Grupo Focal Online Entrevista em profundidade Análise de Conversação
Tabela 3: Algumas ferramentas digitais e métodos já utilizados em suas análises.
Temos no Brasil diversos pesquisadores, grupos, laboratórios e departamentos com um vasto repertório de pesquisa sobre internet: na UFBA, o GITS e o Lab404; na UFMA, o já citado LABCOM; na UFPel, o MIDIARS; na UFF, o MidiCom, o coLAB e o CiteLab; para citar apenas alguns. O Instituto Nacional de Ciência e Tecnologia em Democracia Digital (INCT.DD) tem toda uma rede de pesquisa com grupos de diversas universidades brasileiras voltado a pesquisar comunicação, internet e política. São atores que dão o tom da pesquisa em mídias sociais no Brasil.
Lá fora, além do tão citado DMI, indico também o iNOVA Media Lab, responsável pelo projeto #SMARTDataSprint, que vem desde 2018 atualizando e provocando vários dos paradigmas propostos pelos métodos digitais. Em português, deixo aqui a minha recomentação também para a obra “Métodos Digitais: teoria‐prática‐crítica”, organizado pela pesquisadora Janna Joceli Omena, que traz textos inéditos e traduções de importantes discussões sobre a temática. Em inglês, há o já citado Social Media Lab, a Social Media Research Foundation e a Association of Internet Researchers.
Finalizo este post com o mesmo tom que iniciei: muita calma com essa euforia por dados. Vivemos, de fato, um momento histórico em que nunca houve tantos dados à nossa disposição – e isso vem com várias ponderações, técnicas, ferramentais, éticas e políticas. Tentei apontar aqui algumas delas, mas enquanto pesquisadores acadêmicos acredito que precisamos ter sempre uma responsabilidade social que amplie e atribua as preocupações aos seus devidos lugares, usos e desusos desses meios em vários sentidos.
Também peço calma aos novos navegantes, que foram possivelmente bombardeados com todas essas informações de uma vez só. Eu admito: não li – por completo – todos os livros, teses ou dissertações que cheguei a citar por aqui. Conheço porque chegaram a mim e sei que são importante no cenário geral, mas sei que minha jornada ainda é muito nova para ter todo esse repertório debaixo do braço. O que eu recomendo é pelo menos saber do que se trata cada um desses apontamentos e discussões, para que seja aprofundado quando – e se – necessário.
Acredito também que precisamos pensar coletivamente enquanto comunidade acadêmica sobre essas diferentes perspectivas de se fazer pesquisa: ferramentas, métodos/metodologias e também epistemologias. A sensação que eu tenho é que, no Brasil, ficamos cada um no respectivo cantinho produzindo sobre nossas temáticas e assuntos de interesse, sem necessariamente discutir como estamos desenvolvendo essas pesquisas. A própria lógica e burocracia científica atrapalha de publicação não acompanha a velocidade de tantas mudanças – o que torna ainda mais urgente pensarmos como podemos manter de pé toda essa conversa.
Referências bibliográficas
ALVES, Marcelo. Abordagens da coleta de dados nas mídias sociais. In: SILVA, Tarcízio; STABILE, Max (Orgs.). Monitoramento e pesquisa em mídias sociais: metodologias, aplicações e inovações. São Paulo: Uva Limão, 2016. ARDÈVOL, Elisenda., et al. Media practices and the Internet: some reflections through ethnography. 2008. Apresentação no Simposio del XI congreso de antropología de la FAAEE, Donostia, 10-13 de septiembre de 2008. Disponível em: . Acesso em: 01/02/2010. FRAGOSO, Suely; RECUERO, Raquel; AMARAL, Adriana. Métodos de pesquisa para internet. Porto Alegre: Sulina, v. 1, 2011. HINE, Christine. Ethnography for the Internet: Embedded. Embodied and Everyday (London: Bloomsbury Academic), 2015. RECUERO, Raquel; BASTOS, Marco; ZAGO, Gabriela. Análise de redes para mídia social. Editora Sulina, 2015. RECUERO, Raquel. Redes sociais na Internet. Porto Alegre: Sulina, 2009. VENTURINI, Tommaso; ROGERS, Richard. “‘API-Based Research’ or How Can Digital Sociology and Digital Journalism Studies Learn from the Cambridge Analytica Affair.” Digital Journalism, 2019. WELLMAN, Barry. The three ages of internet studies: ten, five and zero years ago. New Media & Society. London, Vol. 6 Issue 1, p. 123-129, 2004.
No post anterior, vimos os precedentes da análise de redes muito antes de chegarmos às redes sociais na internet (ou aos sites de redes sociais). Em resumo, no primeiro capítulo do e-book, Raquel Recuero apresenta as duas teorias metodológicas fundadoras do pensamento de redes: a Sociometria de Jacob Moreno e a Teoria dos Grafos da matemática. São desses pilares que surge a análise de redes sociais, cuja origem pode ser remontada ainda à primeira metade do século XX. Sua popularização nas últimas décadas é justificada pelo aumento de dados produzidos e disponibilizados na plataformização da vida social e também pelo avanço das técnicas (ferramentais) de análise à disposição de pesquisadores.
Outro fundamento teórico importante o qual a autora resume na primeira parte é referente à ideia de (sites de) redes sociais, a partir principalmente do conceito e discussões propostas pela americana danah boyd. A ideia de “públicos em rede” (ou networked publics) traz características específicas dos sites de redes sociais que permitiram também essa proliferação da análise de redes, sendo elas: a persistência (os registros) das interações/conexões, a replicabilidade, a escalabilidade e a buscabilidade. Tudo isso reitera as dinâmicas de audiências invisíveis, colapso dos contexts e borramento das fronteiras entre o público e o privado encontrado nesses públicos em rede que estão na internet.
A ideia de “redes sociais” é uma metáfora estrutural para que se observem grupos de indivíduos, compreendendo os atores e suas relações. Ou seja, observam-se os atores e suas interações, que por sua vez, vão constituir relações e laços sociais que originam o “tecido” dos grupos. Essas interações proporcionam aos atores posições no grupo social que podem ser mais ou menos vantajosas e lhes dar acesso a valores diferentes. […]
O grafo é, desse modo, uma representação de dois conjuntos de variáveis (nós e conexões). Concebendo uma rede social como uma dessas representações, os nós seriam os atores sociais (compreendendo esses atores como organizações sociais, grupos ou mesmo indivíduos no conjunto analisado) e suas conexões (aqui entendidas como os elementos que serão considerados parte da estrutura social, como interações formais ou informais, conversações etc.).
RECUERO, 2017, p. 23.
O segundo capítulo do e-book segue com foco na teoria por trás das discussões, apresentando diversos conceitos importantes (ou, até mesmo, básicos) para a análise de redes sociais na internet. Ela começa de uma concepção mais geral em torno das redes sociais em sua composição representativa, até chegar nos elementos que as constituem: nós (ou vértices) e arestas (ou laços) – cujas conexões entre eles podem representar diferentes tipos de relações sociais. É a partir daí que elenca conceitos como laços fracos, capital social, homofilia, etc. – cada um desses está diretamente ligado à representação das redes “como sociogramas (grafos sociais), que são analisados a partir das medidas de suas propriedades estruturais”.
É importante ter em vista que a representação dos dados não é somente um artifício visual-estético, mas tem fundamentação nas matrizes matemáticas da teoria dos grafos, que estipulam “as relações entre os atores do grupo” e “servem de base para a estrutura geral da rede”. Nesse mesmo sentido, a representação de uma rede é também uma abordagem teórico-metodológica, em que os nós (ou nodos) podem representar coisas diferentes e até distintas. A autora apresenta como exemplo o caso das redes bimodais, em que nós de uma mesma rede podem representar tanto indivíduos quanto categorias ou grupos.
Exemplo de rede bimodal em que os nós representam 1) imagens e 2) labels associadas a essas imagens
– As conexões: laços sociais [e o conceito de laços fracos]
Tão importantes quanto os nós são as chamadas arestas ou laços (ou, ainda, arcos), que indicam a conexão entre os atores – nas redes sociais, pode representar interação, conversação, relação de amizade/pertencimento, etc. Essa agência necessária, ou seja, o “esforço” ou a “ação” que envolve esse indicador é o que levou Mark Granovetter (1973) a propor uma classificação de laços fortes, fracos ou ausentes: ainda no caso de redes sociais, o primeiro estaria associado a relações de maior proximidade e/ou intimidade, “enquanto os laços fracos representariam associações mais fluidas e pontuais”; por fim, aqueles ausentes “seriam insignificantes em termos de importância estrutural ou completamente ausentes”.
Granovetter (1973, p. 1361) define a “força” do laço como “uma combinação (provavelmente linear) da quantidade de tempo, da intensidade emocional, da intimidade (confiança mútua) e da reciprocidade que caracterizam o laço”. Desse modo, presume-se que a quantidade de interações entre dois atores pode representar, assim, a força da conexão, uma vez que conexões fortes requerem maior investimento do que conexões fracas. A partir dessa discussão, podemos observar que os tipos de laço social representam conexões que são qualitativamente diferentes, e é um desafio importante compreender como a estrutura construída através dos dados e da análise de redes pode, efetivamente, representar esse conceito complexo.
RECUERO, 2017, p. 26.
A autora aponta como, na análise de redes (sociais), “as conexões são representadas de modo numérico e direcional, indicando um valor que é relacionado ao ‘peso’ da conexão” – é, portanto, essa métrica que auxilia na identificação dos tipos de laços sociais existentes entre determinados atores. Lembra também que as conexões (ou seja, as arestas) podem ser direcionadas, como no caso de interações (online ou off-line); ou não direcionadas, como no caso de laços de amizade (do Facebook), por exemplo. Esse (não) direcionamento é fundamental para calcular o peso das conexões.
REDE DIRECIONADA (GRAFO DIRECIONADO)
As conexões possuem direção (geralmente representados por uma seta), ocorre quando as conexões estabelecidas não são iguais (ou não têm o mesmo peso) [p. 36]
REDE NÃO DIRECIONADA (GRAFO NÃO DIRECIONADO)
As conexões não possuem direção ou a direção não importa (geralmente representada por uma linha), mostram uma matriz na qual os dados dessas conexões são exatamente iguais entre os dois atores. [p. 36]
Outro conceito também muito importante que está relacionado aos laços (fortes) é o de clusters ou agrupamento, que é “um conjunto de nós mais densamente conectados (ou mais inteconectados) do que os demais na rede”, ou seja, em que as conexões são mais recíprocas. Essa característica fica evidente na estrutura da rede, em que os nós estão mais próximos “ou porque interagem mais (e suas arestas têm um peso maior) ou porque possuem mais conexões entre si do que com os demais nós da rede”. É justamente essa presença de laços mais fortes que indicam, em termos sociológicos, características mais próximas das definições de comunidade.
– Capital social e os valores das conexões
Recuero também parte do conceito de laços sociais de Granovetter (1973) para introduzir a discussão sobre capital social, cujas formas correspondem às vantagens estruturais das quais os atores se beneficiam (informação, intimidade e reciprocidade). A discussão em torno desse conceito, entretanto, é muito mais complexa e extrapola os estudos de redes sociais em seu caráter metodológico, mas o que interessa aqui é o que está no cerne da expressão: se trata de um capital, há tanto negociação quanto acúmulo (de valores, posições, vantagens, etc.), e esses dois aspectos têm relação direta com as matrizes das redes.
Desse modo, “as trocas sociais implicam na construção de valores cuja percepção por parte do grupo também atua na construção de relações de confiança, resultado dos investimentos individuais na estrutura”. A autora aponta que a maioria dos autores concorda, portanto, que o capital social representa um valor associado à estrutura social – “Burt (1992) argumenta que o conceito é uma metáfora para as transação que caracterizam as interações sociais”, enquanto Putnam (2000) separa dois tipos: bridging (pontes ou laços fracos entre atores de diferentes grupos) e bonding (qualidade/força das conexões ou laços fortes num mesmo grupo).
Estar em uma rede social, assim, permite a construção de valores para os atores. Desse modo, as relações sociais são constituídas de trocas através das quais os atores buscam atingir objetivos e interesses, como um sistema econômico. É preciso investir (interagir) na estrutura social para colher os benefícios. Os valores de capital social são, desse modo, associados a normas de comportamento, participação e às próprias conexões que alguém possui, além de vantagens competitivas advindas desses valores. (BURT, 1992, p. 348)
RECUERO, 2017, p. 29.
Na perspectiva de redes, portanto, os laços sociais (e, portanto, sua posição na estrutura) são como a moeda que garantem acesso a determinados bens, como informações novas e diferentes (mais associados a laços fracos) ou confiança e intimidade (mais associados a laços fortes). Essas vantagens são atribuídas não somente aos indivíduos (ou atores), mas para os grupos sociais (os clusters) como todo, que detêm valores próprios entre si. E além da circulação de informação, mais associado ao conceito de capital social nos estudo das redes, há também outros valores disponíveis em negociação.
BERTOLINI E BRAVO (2004) – tipologia de níveis de capital na rede
Primeiro nível: apropriado de modo individual e relacionado a elementos de laços fracos / tipos: 1) as conexões sociais que os atores possuem, 2) as informações às quais têm acesso e 3) o conhecimento das normas associadas ao grupo que pertencem;
Segundo nível: apropriado de modo coletivo e relacionado a elementos de laços fortes / tipos: 1) a confiança no ambiente social e 2) a institucionalização relacionado ao reconhecimento do grupo como tal.
Outro valor também muito importante na perspectiva dos sites de redes sociais é aquele relacionado à popularidade: “é uma concessão, no sentido de que o ator popular concentra mais capital social, em termos de atenção e visibilidade de seus pares, do que outras pessoas não populares”. Fica ainda mais evidente, neste caso, a relação de apropriação e escassez, em que os próprios recursos de vínculos sociais (a serem investidos ou capturados) são também limitados. Recuero retoma o trabalho de Barabási (2003) sobre a presença de conectores (grupos pequenos muito conectados entre si) para complementar o argumento de que todos detemos de capital social, mas a sua lógica própria exige a distribuição desproporcional de recursos.
– Homofolia, [Pontes, Conexões Reduntantes,] Buracos Estruturais e Fechamentos
O conceito de homofilia, de modo simplificado, diz respeito à ideia de que “pessoas mais próximas tendem a ter interesses comuns e padrões de comportamento semelhantes”, seja isso tanto efeito quanto causa. Ou seja, um grupo social pode ser identificado enquanto tal justamente por agregar pessoas “parecidas”, o que resulta “no fato de que esses atores tendem a ter acesso às mesmas fontes e a circular as mesmas informações”. Essa característica, portanto, também se relaciona ao capital social, “uma vez que pode auxiliar na construção e no fortalecimento dos laços sociais que vão gerá-lo”.
Outro conceito também muito importante nas redes sociais são as chamadas conexões “pontes“, aquelas que se conectam a vários grupos, transitando em círculos variados e aproximando grupos distantes/diferentes entre si. São fundamentais para que as informações circulem na rede, formadas geralmente de laços fracos. O conceito de “buraco estrutural” parte dessa ideia, em que os buracos “representam a ausência de conexões entre dois nós que possuem grupos/fontes informativas complementares ou não redundantes”.
Um cluster geralmente tem conexões redundantes, ou seja, conexões que interligam o mesmo conjunto de nós. Já conexões não redundantes são aquelas que interligam os atores de diferentes grupos. Conexões redundantes o são porque nelas circulam as mesmas informações. Já as não redundantes são aquelas capazes de trazer informações novas para o grupo. Assim, como dissemos, as conexões transmitem informação e estão relacionadas ao conceito de capital social. O buraco estrutural, portanto, representa uma falha no caminho de transmissão de informações, que poderia dar acesso a fontes de informação diferentes para os dois grupos em questão. Desse modo, aqueles atores que fazem a “ponte” (ou mediação) entre diferentes grupos possuem uma vantagem em relação aos demais, pois têm acesso a tipos diferentes de informação, enquanto que os buracos estruturais representam uma desvantagem para os grupos.
RECUERO, 2017, p. 32.
Já a ideia de “fechamento da rede” é o oposto dos buracos estruturais: “é a qualidade associada a todos os nós de uma determinada rede estarem interconectados”. Está associada aos chamados clusters, que são grupos mais fechados entre si (atores que compartilham de mais conexões uns com os outros) – cujo fechamento completo (inteiramente conectado) é chamado de clique, “um grupo em que todas as conexões possíveis existem”. Assim como o conceito de homofilia, pontes, conexões reduntantes e buracos estruturais, também corresponde à noção de capital social por operar no intercâmbio relacional da rede.
– Graus de separação [e estrutura de mundo pequeno]
Vimos na primeira parte que um dos fundamentos da Teoria dos Grafos é o enigma das Pontes de Königsberg, em que foi feito a tentativa de calcular qual era a distância mínima entre dois pontos sem repetir um mesmo caminho. Na perspectiva das redes, isso veio a se chamar de “grau de separação”, ou seja, a distância entre dois nós. As métricas de “caminho médio” ou “distância média” (average path) calculam justamente o caminho médio mais curto entre todos os nós da rede, podendo indicar “o quão interconectada está a rede pelos diversos laços existentes”.
Recuero parte do conceito de grau de separação para falar da teoria de mundo pequeno, que foi apropriada no estudo de redes de modo que “uma rede mundo pequeno é aquela em que um conjunto de nós é aproximado na rede por algumas conexões, que terminam por reduzir a distância (grau de separação) entre todos os nós na estrutura”. A importância aqui está no fato de que nós (ou indivíduos) mais conectados (mais conhecidos) podem diminuir significativamente a distância entre os demais atores da rede.
A estrutura de mundos pequenos, assim, é encontrada em redes sociais e está relacionada à presença de “pontes” entre os vários nós da rede e à redução do “caminho” (path) entre dois nós quaisquer da rede pela presença dessas conexões, que são apresentadas por autores como Granovetter (1973) e Watts e Strogats (1998) como conexões fracas ou associadas aos laços fracos, e portanto, ao capital social do tipo bridging de Putnam (2000), pois permitem que os atores tenham acesso a fontes diferentes de informações
RECUERO, 2017, p. 34.
REDE EGO
A estrutura é desenhada a partir de um indivíduo central, determinando, a partir desse “ego”, um número de graus de separação; [p. 37]
REDE INTEIRA
É mapeada na sua integridade, quando é possível limitar essa rede de modo externo [p. 37].
Recapitulando, neste post (e neste segundo capítulo) vimos os conceitos de: redes sociais, nós/vértices e conexões/arestas, redes bimodais, laços fracos/fortes/ausentes, redes direcionadas e não direcionadas, clusters, capital social, briding/bonding, homofilia, pontes, conexões redundantes, buracos estruturais, fechamentos, graus de separação, estrutura de mundos pequenos, redes ego e redes inteiras. Anotou tudo?
Referências citadas neste capítulo
BURT, R. The Social Structure of Competition. In: BURT, R. Structural Holes: the social structure of competition. Cambridge: Harverd University Press, 1992.
BARABÁSI, A. Linked: How everything is connected to to Everything Else and What It Means for Business, Science, and Everyday Life. New York: Basic Books, 2003.
GRANOVETTER, M. S. The Strength of Weak Ties. American Journal of Sociology, Chicago, v. 78, n. 6, p. 1360 – 1380, 1973.
PUTNAM, R. D. Bowling Alone: The collapse and Revival of American Community. New York: Simon e Schuster, 2000.
WATTS, D.; STROGATZ, S. Collective dynamics of ‘small-world’ networks. Nature, [S.l.], v. 393, p. 440-442, 1998.
Em abril de 2017, publiquei aqui no blog o texto “A minha saga com redes sociais (ou por que é importante compreendê-las)“, no qual contava um pouco da minha relação com redes sociais enquanto abordagem teórico-metodológica. Nesta época estava começando a escrever meu TCC (sobre identidade nordestina em sites de redes sociais) e tinha acabado de dar início também (como relato no post) ao curso de Análise de Redes para Mídias Sociais do IBPAD. Em dezembro desse mesmo ano, Raquel Recuero lançou pela Coleção Cibercultura/Lab404 da EDUFBA um e-book introdutório sobre análise de redes sociais online.
Com certeza o Pedro de 2017, ainda bastante resistente a análise de redes, não esperava que tudo isso fosse (ou sequer poderia) acontecer. E faço essa introdução porque esta série que inicio com este post tem também essa função incentivadora (assim como foi a palestra no SMWSP), para aqueles que têm vergonha de perguntar, que tem medo ou que acham desnecessária (ou demasiadamente “quantitativa”, como era o meu caso) essa abordagem teórico-metodológica. A ideia é utilizar a excelente publicação de Raquel Recuero para a editora da UFBA como fonte teórica e propulsora para uma iniciação ao trabalho de análise de redes para mídias sociais.
É importante salientar que há outra obra, mais completa e publicada por Recuero em parceria com Gabriela Zago e Marcos Bastos em 2015, “Análise de Redes para Mídia Social” (Editora Sulina). O e-book produzido para a Coleção Cibercultura/Lab404 da UFBA é, como o próprio nome já indica, uma introdução à temática, ainda que traga novas referências como fruto da própria experiência de aprendizado constante da autora. Trata-se de uma obra condensada, “uma pequena compilação dos principais conceitos e elementos da ARS” cujo norte “está na busca das aplicações empíricas e no aprendizado pela prática”.
Esse “guia introdutório e simplificado de conceitos, práticas e formas de análise” está dividido em quatro capítulos: 1. O que é Análise de Redes?; 2. Quais são os principais conceitos de ARS?; 3. Quais são as principais métricas de Análise de Redes? 4. Como coletar, analisar e visualizar dados para Análise de Redes?. Os títulos como perguntas reitera a proposta direto ao ponto da obra, em que cada parte do texto é desencadeada conforme as discussões abordadas, “fornecendo as bases para a compreensão de como fazer análise de redes e a seguir, trazendo elementos complementares”. Neste primeiro post, sigamos apenas com o primeiro capítulo.
O QUE É ANÁLISE DE REDES?
O primeiro esforço que a autora faz é o de deixar claro que a análise de redes sociais é uma abordagem para analisar grupos sociais, ou seja, é muito anterior (quase um século) à análise de redes online. Suas premissas metodológicas, com respaldo teórico, têm fundamento (ou raízes) na Sociometria e na Teoria dos Grafos, as quais serão explicadas mais adiante. De modo simplificado, a análise de redes (sociais) é uma perspectiva teórico-metodológica que permite estudarmos estruturas e fenômenos sociais como redes.
“A rede dentro da qual qualquer indivíduo está inserido (ou seu grupo social) é também a responsável por uma grande parcela de influência sobre esse indivíduo. O lugar de alguém na estrutura social advém de uma série complexa de relações, da qual emergem normas, oportunidades e, inclusive, limitações. […] Ou seja, a percepção da estrutura em torno dos atores é fundamental para que possamos compreender também seu comportamento. Além disso, o comportamento individual dos atores reflete-se na rede como um todo, moldando-a e adaptando-a, sendo também, portanto, fundamental para que possamos compreender a estrutura em si.”
RECUERO, 2017, p. 13.
Ela complementa que “a ideia que embasa os estudos das estruturas sociais é aquela de que os indivíduos, os atores sociais, estão inseridos em estruturas complexas de relações com outros atores”. Os grupos sociais (família, escola, trabalho, etc.) os quais nós enquanto indivíduos fazemos parte “têm um papel fundamental no [nosso] comportamento e na [nossa] visão de mundo”, em que as relações que estabelecemos conferem determinadas posições nas redes, que são tanto produto quanto produtora das interações e associações.
– De onde vem a Análise de Redes Sociais?
A origem da análise de redes sociais pode ser creditada a variados campos do saber (numa perspectiva interdisciplinar) no início do século XX, sobretudo a partir da década de 30. A posição da autora a é de seguir com o consenso estabelecido pela revisão literária de que há dois pilares fundadores: a Sociometria e a Teoria dos Grafos, “embora traços dos conceitos possam ser observados em trabalhos muito anteriores”. Sociologia, Antropologia e Psicologia são apenas algumas das disciplinas que, ancoradas na contribuição da Matemática, começaram a esquematizar um método para a análise de redes sociais.
Scott (2001) credita o “nascimento” da ARS como abordagem ao desenvolvimento da Sociometria, que trouxe sistematização analítica a partir de fundamentos da teoria dos grafos. Já o desenvolvimento desse método, o autor atribui aos pesquisadores que, na década de 1930, passaram a estudar os padrões de relações e a formação de grupos sociais como cliques e, finalmente, aos antropólogos que a partir desses elementos começaram a estudar os conceitos de “comunidade”. Para o autor, são essas tradições que vão formar aquilo que, na década de 1960, vai se constituir na tradição dos estudos de análise de redes.
RECUERO, 2017, p. 14.
A sociometria é a denominação dada à abordagem de Jacob Moreno na invenção do sociograma (1930), “a representação da rede, no qual os atores sociais são apresentados como nós, e suas conexões, representadas por linhas que unem esses nós”. Os estudos do psicólogo, com ajuda da sua colaboradora Helen Jennings, tinha como objetivo “medir as relações dos grupos, compreendendo […] como esses conjuntos de atores eram estruturados”. Foi fundamental para direcionar o foco à “estrutura social para que se compreendesse a dinâmica dos grupos”, embora só tenha sido desenvolvida (reabordadas por outros grupos) como análise de redes após a década de 50.
Já a Teoria dos Grafos foi responsável por fornecer “formas mais sistemáticas de medida […]” das estruturas sociais, cuja teorização das redes dispõem as principais métricas para a compreensão das posições dos nós e de sua própria estrutura. É uma disciplina da matemática “que estuda conjuntos de objetos e suas conexões”, cuja origem estaria “no trabalho de Ëuler e na solução que ele propôs para o enigma das Pontes de Königsberg”. Cartwright e Harary teriam sido os primeiros a aplicar grafos à leitura dos sociogramas de Moreno, o que permitiu “que novas perspectivas fossem compreendidas dentro da dinâmica dos grupos sociais”.
Mas se a análise de redes sociais tem sua consolidação em meados do século XX, com sementes originárias datando de décadas antes (até Simmel e Weber, por exemplo), por que há uma crescente popularização dessa abordagem? Recuero credita isso à “ampliação do foco do estudo de grupos pequenos para grupos em larga escala”, fazendo com que novas disciplinas cruzem fronteiras entre as Ciências Exatas e Ciências Sociais e Humanas. Duas justificativas para esse novo contexto da análise de redes sociais possa surgir são: “a disponibilização de dados sociais, especialmente pelas ferramentas digitais de comunicação” e; “o uso de métodos computacionais, que permitiram a coleta e a análise desses dados sociais”.
– Redes sociais e sites de redes sociais são a mesma coisa?
Em julho de 2019, a autora publicou no Medium o texto “Mídia social, plataforma digital, site de rede social ou rede social? Não é tudo a mesma coisa?”, somente dois anos após o lançamento do e-book. Essa é uma pergunta que provavelmente deve continuar sendo feita ainda por muito tempo, mesmo com todos os (constantes) esforços para respondê-la. O problema está principalmente no fato de que, no Brasil, chamamos tudo de “rede social”; no entanto, como a própria discussão da origem das análises de redes sociais já indica, redes sociais são muito “anteriores” aos sites de redes sociais.
O argumento apresentado no e-book parte do conceito primeiro proposto pelas autoras danah boyd e Nicole Ellison em publicação de 2007 (a data é importante para contextualizar o momento pelo qual a internet passava, pensando Facebook, Orkut, etc.) que “algumas ferramentas online apresentam modos de representação de grupos sociais baseados nas relações entre os atores”. Seriam características dessas: “(1) permitir que os atores construam um perfil público ou semipúblico; (2) permitir que esses atores construam conexões com outros atores; e (3) permitir que esses atores possam visualizar ou navegar por essas conexões“.
“Enquanto uma rede social está relacionada à percepção de um grupo social determinado pela sua estrutura (a “rede”), que é geralmente oculta, pois só está manifesta nas interações, as ferramentas sociais na internet são capazes de publicizar e influenciar essas estruturas sociais. (BOYD; ELLISON, 2007) Ou seja, o Facebook, por si só, não apresenta redes sociais. É o modo de apropriação que as pessoas fazem dele que é capaz de desvelar redes que existem ou que estão baseadas em estruturas sociais construídas por essas pessoas […].”
RECUERO, 2017, p. 16.
Sites não necessariamente refletem redes sociais do espaço offline, mas “amplificam conexões sociais, permitem que estas apareçam em larga escala (RECUERO, 2009) e também atuam de modo a auxiliar na sua manutenção”. Pessoas que você conhece (ou conheceu) offline, por exemplo, podem manter uma conexão com você no Facebook devido à facilidade de manutenção desse laço fraco; ou, ainda, pessoas que você não conhece offline podem aparecer no seu news feed enquanto perfil ou até mesmo publicações, devido à característica própria da ferramenta. As redes sociais na internet, portanto, “são outro fenômeno, característico da apropriação dos sites de rede social.”
Outro conceito que Recuero traz de boyd para diferenciar os sites de redes sociais (e, portanto, as redes sociais online) é o de “públicos em rede” (networked publics). “Embora esse conceito não esteja diretamente relacionado com análise de redes, ele auxilia a compreensão de como os sites de rede social influenciam os processos de representação dos grupos“, explica. São affordances que explicitam “elementos que emergem das características técnicas dessas ferramentas e suportam suas apropriações“:
Persistência: interações/conexões dos meios online permanecem no tempo (podem ser recuperadas); o que permite que a conversa seja assíncrona (atores não estão presentes ao mesmo tempo), ampliando “as possibilidades de manutenção e recuperação de conexões e valores sociais”.
Replicabilidade: como as interações/conexões permanecem, são mais facilmente replicadas (podem circular mais rápida e fidedignidamente);
Escalabilidade: a junção de esses dois elementos permite que as informações percorram toda a estrutura de redes (viralidade);
Buscabilidade: devido à permanência (registro), as informações podem ser buscáveis.
“São esses elementos que proporcionam os contextos nos quais podemos perceber como as redes sociais na internet podem ser diferentes em suas apropriações e práticas sociais, e na circulação de informações das redes sociais offline.”
RAQUEL RECUERO
Ainda pensando num contexto mais conversacional (e não de laços estabelecidos, como amigos/seguidores – ou conexões associativas, para utilizar o conceito da própria), Recuero também recupera boyd para destacar as dinâmicas dos públicos em rede. O foco dessas outras características, entretanto, estaria no modo como “influenciam as redes sociais que emergem desse processo”:
Audiências invisíveis: diferente das redes offline, em que a autora argumenta que conseguimos “peceber” com mais facilidade (por ser menor e menos conectada), as redes de SRSs são “imediatamente discerníveis” pelas “audiências que rodeiam as interações no espaço online”.
Colapso dos contextos: ao permanecerem e serem replicadas, deslocamentos de contextos são comuns, o que potencializa a possibilidade de conflitos entre grupos distintos.
Borramento das fronteiras entre o público e o privado: diz respeito à “dificuldade em demarcar espaços que são tipicamente dados nos grupos sociais offline” (família, amigos, etc.), o que “acaba por expor os atores, aumentando a percepção de intimidade e sua participação pela rede”.
– Para que serve a ARS?
Como mencionado anteriormente, a análise de redes sociais tem se popularizado devido a dois fatores principais: “graças ao aumento da quantidade de dados sociais disponibilizados por conta dos usos das ferramentas de comunicação mediada pelo computador” e, também, “por ser uma abordagem bastante propícia para o estudo e a visualização de grandes quantidades de dados”. É nesse contexto que tem sido utilizada em áreas como Comunicação Social e Sociologia Computacional, “para compreender fenômenos associados à estrutura das redes sociais, principalmente, online”.
A autora encerra o primeiro capítulo, portanto, listando os cenários em que a análise de redes sociais pode ser utilizada: 1) estudos das relações entre os elementos da estrutura do fenômeno; 2) estudos nos quais o objeto possa ser estruturalmente mapeado; 3) estudos nos quais o problema de pesquisa foque um conjunto de dados passível de ser coletado e mapeado com os recursos disponíveis. Ela está chamando a atenção para o fato de que nem toda pesquisa cabe uma abordagem de redes, por isso é preciso ficar atento a esses “critérios” básicos e se perguntar: a resposta que eu preciso responder pode ser alcançada com a análise de redes?
Se você quer identificar como o capital social é constituído em determinado grupo, como a informação circula num determinado grupo social ou quais são os subgrupos – ou clusters – dentro de uma grande grupo – ou rede, por exemplo, sim. Se o objeto pode ser mapeado e sua estrutura será visível (os dados são acessíveis), também. Se há a possibilidade de realizar todo o processo, de mapeamento à coleta e posterior análise seguindo as premissas metodológicas da análise de redes sociais, também.
Referências citadas neste capítulo
SCOTT, J. Social Network Analysis: Ahandbook. 2. ed. New York: SAGE, 2001.
BOYD, D.; ELLISON, N. Social Network Sites: Definition, History, and Scholarship. Journal of Computer-Mediated Communication, [S.l.], v. 13, n. 1, p. 210-230, 2007.
BOYD, D. Social Network Sites as Networked Publics: Affordances, Dynamics, and Implications. In: PAPACHARISSI, Z. (Ed.). ANetworked Self: Identity, Community, and Culture on Social Network Sites. New York: Routledge, 2010. p. 39-58
BRUNS, A. et al. #qldfloods and @QPSMedia: Crisis Communication on Twitter in the 2011 South East Queensland Floods. Brisbane, Qld: ARC Centre of Excellence for Creative Industries and Innovation, 2012.
BRUNS, A.; BURGESS, J. E. Researching news discussion on Twitter: New methodologies. Journalism Studies, Florida, v. 13, 2012.
DEGENNE, A.; FORSÉ, M. Introducing Social Networks. London: SAGE, 1999.
FREEMAN, L. The development of social network analysis: a study in the sociology of science. Vancouver: Empirical Press, 2004.
MALINI, F. Um método perspectivista de análise de redes sociais: Cartografando topologias e temporalidades em rede. In: ENCONTRO DACOMPÓS, 25., 2016, Goiânia. Anais… Campós: Goiânia, 2016. Disponível em: http://www.compos.org.br/biblioteca/compos_malini_2016_3269.pdf. Acesso em: 23 de maio de 2017
RECUERO, R. Redes Sociais na Internet. Porto Alegre: Sulina, 2009.
RECUERO, R. A Conversação em Rede: comunicação mediada pelo computador. Porto Alegre: Sulina, 2012.
RECUERO, R. Contribuições da Análise de Redes Sociais para o estudo das redes sociais na Internet: o caso da hashtag #Tamojuntodilma e #CalaabocaDilma. Revista Fronteiras, São Leopoldo, v. 16, p. 60-77, 2014.
RECUERO, R.; BASTOS, M. T.; ZAGO, G. Análise de Redes para Mídia Social. Porto Alegre: Sulina, 2015.
WASSERMAN, S.; FAUST, K. Social Network Analysis: methods and aplications. Cambridge: Cambridge University Press, 1994.
Passeando pelo Twitter algumas semanas atrás, me deparei com o da user @lhonoratus que reproduzo abaixo. Chegou até mim através de um retweet de uma amiga, que respondia à provocação da usuária compartilhando uma dessas situações absurdas com que teve que lidar diante de sudestinos. Eu, particularmente, acho essa categoria muito interessante por si só, pensando que é uma “identidade” que tenho visto pipocar principalmente no Twitter já há alguns anos, no mesmo tom desse tweet que chegou até mim. Acho que essa exploração já rende muita discussão, mas aqui tentei focar apenas neste caso.
Conte aqui o maior absurdo que um sudestino ja te disse
Com as mais de 300 respostas que o tweet recebeu, além de os outros modos em que os usuários se apropriaram da mensagem (em resposta como retweet de citação), fiquei realmente curioso para descobrir quais eram esses absurdos. Vasculhando pelas respostas do próprio tweet e conhecendo também o contexto de ambas as categorias de sujeitos, já tinha algumas hipóteses: provavelmente muitas situações constrangedoras (para não falar revoltantes) sobre sotaque/modos de falar, estereótipos direta ou indiretamente associados a classe, etc. – toda a construção que evoca a imagem do nordestino no “encontro” com o outro.
Para testar essas hipóteses, fiz a coleta com o twint (script em Python que faz raspagem de dados do Twitter) de todos os tweets tanto em resposta ao tweet original quanto em formato de citação. Ao total, foram 1.542 tweets de 1.239 usuários diferentes – ou seja, bastante absurdo para ser investigado (embora não possamos afirmar que todos esses 1.500 tweets trazem mensagens correspondentes à proposta do original, visto que podem ser só respostas outras, comentários, etc.). A rede abaixo foi gerada com todo esse montante de dados, tratada no WORDij e elaborada no Gephi com técnicas direcionadas à análise de redes semânticas.
A rede foi feita a partir da co-ocorrência entre os termos, ou seja, as conexões que se são representam uma certa “proximidade” disursiva. Foram, ao total após o tratamento, 472 palavras, cuja frequência está de acordo com o tamanho proporcional em que se apresenta na rede. Os laços (as conexões que ligam um termo a outro) também estão com certo peso evidente, conforme o tamanho das linhas – ou seja, quanto mais grossa, mais “forte” a conexão entre as palavras (aparecem juntas com mais frequência). As cores indicam os agrupamentos feitos através da modularidade (própria do software), e nos ajuda a encontrar alguns territórios semânticos específicos.
No entanto, este é um exemplo bem interessante de como a modularidade nem sempre dá conta de “compreender” a complexidade da rede. Os doze clusters identificados pelo software podem ser compreendidos, conforme a minha interpretação, da seguinte forma: desconhecimento/ignorância (29% dos termos, “perguntou” como referência); “elogios” ao revés (27%, “nordeste”); sotaque/fala (15%, “sotaque”); praia/turismo (7%, “pessoa”); comentários (6%, “sudestinos”); cenas do cotidiano (4%, “rua”); deboche/constrangimento (3%, “mudou”); banho (3%, “paulo”); matar (1%, “vontade”); trabalho (-1%, “respondi”); fenótipo (-1%, “olho”); noção (-1%, “nenhuma”).
Esses grupos delimitados por critérios mais quantitativos e identificados em seu contexto semântico/social a partir da minha própria interpretação são um bom direcionamento para entender algumas das respostas que encontramos, mas se os pensarmos individualmente acabamos por ignorar – e, de certo modo, até mesmo ter uma visão equivocada dos – discursos em suas multiplicidades. Em outras palavras, praticamente todos esses clusters (ou melhor, os termos que os constituem) dialogam uns com os outros (ou seja, com termos de diferentes clusters). E a própria configuração do modo como se apresentam foi uma decisão minha, após alguns testes.
"nossa mas tu é tao branquinha nem parece que é do nordeste"
O cluster laranja, por exemplo, que chamei de “elogios” ao revés, se estende por boa parte da rede, o que demonstra o quanto carrega certa coesão entre si, mas também tem ligação direta com outras palavras. Em sua localização mais acima, está associado a um determinado modo do que se espera de um nordestina – e diretamente também ligado especificamente à fala, o que corresponde à proximidade com o sotaque. Há, entretanto, para além da fala (que pode ser tanto em sua entonação “cantada” quanto em seu caráter mais distintivo, “educado”), uma associação também a um certo fenótipo racializado – e, aqui, em contexto de surpresa, de inesperado.
Mais abaixo, esse mesmo cluster ainda mantém sua proximidade (e conectividade) com as respostas que destacam especificamente o sotaque (“estranho”, “forte”, “diferente”, “feio”), mas já segue para outro caminho em direção a dimensões semânticas mais generalistas. Há uma aproximação tanto a certos termos relacionados a hábitos alimentícios quanto a algumas outras palavras mais soltas na rede, que ainda assim se localizam dentro de algumas características também estereotipadas. É o caso, por exemplo, da conexão com as perguntas sobre “água” e, mais abaixo, a peixeira e a canoa. Esses que se conectam com cenas do cotidiano e mitos do banho.
no nordeste tem SEMÁFORO? COMO ASSIM??? E como assim as ruas n são de barro? https://t.co/wtfk2P8Ia5
Do outro lado, mas ainda bastante ligado a esses outros dois maiores clusters, o azul que chamei de desconhecimento/ignorância (talvez por falta de palavras mais assertivas) também se expande por boa parte da rede, mas que – pelo menos na minha interpretação – tem como ponto de encontro a desinformação (ou estupidez mesmo). Aqui são os termos mais diretamente associados às situações do encontro, em que os usuários contaram as perguntas absurdas que tiveram que ouvir – e que, novamente, reproduzem estereótipos voltados sobretudo para um recorte de classe muito bem estabelecido, que deduz uma suposta carência da região Nordeste.
Pelas respostas podemos constar:
– Sudestino é FISSURADO em shopping e McDonald's – O currículo de geografia nas escolas sudestinas tá meio fraco, não é possível – Pra eles no Nordeste não tem água, nem gente branca, nem pão – Assistam Bacurau!
Um pouco mais distante do centro, é também esse cluster que aponta para mais uma fixão do estereótipo nordestino: o do local para turista ver (e visitar) – é como (e onde) surgem os termos sobre viagem, também ligados a algumas cidades e estados específicos. É também nesse contexto de visita que há um retorno à ignorância para as perguntas sobre “onde” exatamente no Nordeste, tanto por um desconhecimento da constituição geográfica da região quanto por uma generalização ignorante de que todas as pessoas que moram em cidades localizadas nela se conheceriam ou teriam algum nível de proximidade/intimidade.
"Tu é da onde?" Eu – São Luis do Maranhão " Vish longe né, deve ter sido sofrido ate chegar aqui" Eu – Menino eu vim numa coisa chamada avião, não sei se tu ja ouviu falar" (O cidadão na mesma hora mudou de assunto)
Acho que vale ainda destacar que todos esses absurdos nem sempre são ouvidos sem com que as pessoas reajam de algum modo mais contundente. O cluster de comentários (“sudestino”, “ouvi”), por exemplo, aponta para o estafamento dessas situações e que dialoga diretamente com o grupo de deboche/constrangimento (“assustado”, “vergonha”). Ou seja, quem fala o que não deve ouve o que não quer: nordestinos, justamente nessas situações constrangedoras/desgastantes, operam astuciosamente para não apenas se livrar daquele desconforto, mas para transferi-lo diretamente para quem os colocou nessa posição.
É uma rede que com certeza pode ser ainda mais (e melhor) explorada e assim pretendo fazer em outra oportunidade mais propícia. Quis trazer aqui para já levantar alguns apontamentos e percepções iniciais, que dialogam também com meu projeto de mestrado. Como próximo passo, talvez tentar ir ainda mais a fundo em todas as nuances das respostas e já dialogar com alguns autores que pensaram esse preconceito de origem geográfica e de lugar, sem perder de vista seu assentamento em classe e raça. No mais, problematizar também os benefícios e os limites da metodologia de análise de redes semânticas.
Memórias, relatos e registros autobiográficos podem ser importantes fontes para o trabalho de historiadores, pois constroem uma história “mais humana”, ao contemplar diferentes estratos sociais e grupos étnicos (e não apenas a elite) – entre acadêmicos, a área é conhecida como “história da vida cotidiana”. Historiadores cruzam esses materiais com outras fontes (como reportagens publicadas na imprensa ou informes oficiais do governo) para analisar uma época.
Juliana Sayuri, UOL TAB
Sem sombra de dúvidas, estamos vivendo uma das crises globais sobre a qual teremos maior documentação histórica disponível. E uma das fontes mais ricas – e caóticas, ou complexas – para as narrativas dos tempos atuais é a internet. Portanto, quando, no mesmo dia que li essa matéria, surgiu na minha própria timeline do Twitter um relato pessoal explicitamente narrado como “diário de quarentena”, surgiu a curiosidade: o que será que as pessoas estão relatando sobre o seu dia a dia no microblog mais popular da internet?
Antes de seguir nessa jornada, é importante dar um passo para trás e entender o contexto sociocultural no qual a plataforma está inserida principalmente em suas funcionalidades de uso no Brasil. Trata-se de um site de rede social pautado em lógicas de capital social (curtidas, retweets, seguidores) no qual os usuários, (in)voluntariamente, disputam por maior visibilidade. Além disso, é também um espaço cujo público recorrente se difere bastante do Facebook e Instagram, por exemplo, o que condiciona diretamente o que compartilhamos e deixamos de compartilhar.
De modo muito resumido, é por isso que o título desse post não é “Diários da Quarentena: relatos de brasileiros em reclusão”, pois compreendo os limites metodológicos que se enquadram na fonte de dados disponível. É importante ter em vista o que leva uma pessoa a publicar, sobretudo em formato de “diário” (e o que envolve essa compreensão no imaginário social), sobre suas questões e anseios do cotidiano. A proposta aqui é bastante específica: identificar quais são as temáticas sobre as quais usuários brasileiros do Twitter enunciam como diário.
Dito isso, podemos seguir com a metodologia: utilizei o twint para coletar os tweets (agradeço especialmente a meu colega de trabalho, Lucas Neves, do IBPAD, que me ajudou com alguns tropeços nessa coleta), com o termo de busca “diário de/da quarentena”, entre os dias 10 de março e 27 de abril. Importante lembrar, como já sinalizei em outro post, que esse script não coleta retweets (pois faz raspagem, e não acesso via API), o que novamente não é um problema, visto que para os fins desta análise faz mais sentido trabalhar apenas com conteúdos originais.
Utilizei o WORDij parar criar um arquivo de co-ocorrência de palavras que, trabalhado com técnicas de análise de redes no Gephi, me permitiu gerar o grafo que compartilho abaixo. Duas considerações importantes: 1) excluí a menor quantidade de nós (palavras) possível, para que fosse possível navegar a rede e encontrar conexões interessantes (são 8.565 palavras com 62.635 conexões entre elas); 2) executei a modularidade (algoritmo de detecção de comunidades) com valor de resolução menor que o padrão, para tentar identificar o máximo de grupos possíveis.
E são essas duas considerações que “explicam”, de certa forma, a rede estar tão truncada: são muitos nós (palavras) e muitos clusters (coloridos) pequenos/médios. Vale ratificar que o valor extremamente alto de conexões (arestas) também colabora para esse cenário, o que – tecnicamente – dificulta a distribuição de agrupamentos bem delimitados e – analiticamente – aponta para uma utilização constante das mesmas palavras em diferentes distribuições de sentenças (ou seja, é um vocabulário limitado de termos repetidos em várias frases). O que ajuda a encontrar as temáticas, portanto, é a granularização da modularidade.
Ao todo, com o algoritmo de detecção de comunidade do Gephi, consegui identificar 29 territórios semânticos – desde os mais generalistas/conectores até os mais específicos/temáticos. O maior cluster, por exemplo, que denominei “Narrativa”, é composto por termos de apoio (conectores narrativos) aos demais – o mesmo acontece com o grupo “Conectores”. Já os demais possuem particularidades que nos permitem, numa análise conjuntural, delimitar mais especificadamente do que se trata cada um deles – e tentei indicar nomenclaturas suficientemente autoexplicativas.
Nessa direção, a partir dos grupos identificados pela modularidade e sua análise conjuntural, proponho quatro pilares temáticos da conversa: 1) reclusão e ansiedade; 2) pandemia e ansiedade; 3) rotina e atividades; 4) prazer e lazer (a ordenação não segue parâmetro de volumetria, apenas organização descritiva). O primeiro contempla os grupos de inquietudes, (perda da) noção de tempo, emoções, carências sociais, interações familiares, família e amigos, saudades, vontades e desejos. É também uma resposta ao contexto social escancarado pelo segundo, em que o isolamento social se faz necessidade para combater a fatalidade do vírus frente a um cenário político tenebroso.
Por outro lado, em rotina e atividades, onde os usuários comentam sobre o dia-a-dia da quarentena e suas particularidades, desde tarefas domésticas, passando pelos (novos) hábitos de compra de mercadorias, até movimentos de auto-cuidado com a beleza (ou surtos capilares) e a (nova) rotina de aulas de ensino (a distância). Também nesse contexto mais leve, associam-se os termos de prazer e lazer, no qual estão presentes termos relacionados ao consumo audiovisual (Netflix, YouTube, séries, etc.), consumo musical (lives/shows online, Spotify, etc.), jogos (de PC, celular, ou até mesmo correntes) e também leitura.
Destaque auto-centrado da palavra (do nó referente a) “banheiro” e suas conexões nas proximidades
Todos esses subgrupos referidos nas descrições das quatro grandes temáticas estão devidamente apontados na rede interativa – e, portanto, podem ser ainda mais explorados. Além de avaliar os clusters individualmente, vale também navegar pelos termos livremente para perceber como, ainda que haja certa coerência cognitiva entre os agrupamentos semânticos delimitados pela modularidade, as palavras aparecem em diferentes contextos e cenários em associação também aos demais clusters do qual eventualmente não faz parte (como no exemplo acima).
Seria também interessante avaliar a sazonalidade dessas temáticas, tanto no de dias da semana (o que se faz no final de semana difere do restante?, por exemplo) quanto na própria eventual evolução de hábitos de comportamento durante o período da quarentena (os usuários começaram fazendo exercícios e depois passaram a comentar mais sobre receitas?, por exemplo). Essa visão temporal pode acrescentar bastante à análise e ajudar a compreender o cenário de modo ainda mais criterioso. Para os fins que elegemos, entretanto, paramos por aqui hoje; mas, quem sabe num próximo post?
De tempos em tempos, usuários do Twitter aderem a novas tendências ou piadinhas “internas” que, na maioria das vezes, acaba se proliferando para outros espaços da web. No final de maio deste ano, o site foi tomado pela seguinte frase: “this represents Brazil more than soccer and samba” (isso representa o Brasil mas do que futebol e samba, em tradução livre) – que vinha sempre acompanhada de uma ou mais imagens. Tudo começou com o seguinte tweet (pelo menos foi o mais antigo que consegui encontrar) do usuário @Celso_Piazzi10 que rapidamente viralizou:
Rapidamente milhares de usuários entraram na onda e começaram também a publicar imagens que, de alguma forma e/ou por algum motivo, representavam o Brasil melhor do que futebol e samba. Como era de se esperar, alguns portais de notícia/entretenimento – como o Buzzfeed, JC, Vix, Atlântida – começaram também a fazer suas próprias matérias sobre o assunto, através de curadorias que muito provavelmente levavam (apenas) em conta o número de engajamento daquelas mensagens – ou seja, quem tinha mais retweet tinha maior visibilidade.
Na época, cheguei a conversar com Toth, do Data7, que seria legal fazer algum tipo de análise que fosse além dos tweets mais engajados e olhasse aquele movimento como um todo. Ele chegou a coletar uma base para mim (e deixo aqui meu agradecimento público!), mas acabei não levando para frente. Algumas semanas atrás, relembrei dessa ideia ao descobrir o twintproject – uma ferramenta em Python para raspar tweets sem utilizar a API – e resolvi retomar esse projeto. Com a ajuda de Carol, coletamos +5.000 tweets entre maio e outubro deste ano.
Esses tweets somaram cerca de 6.000 imagens (já que alguns tweets continham mais de uma imagem em sua composição), ainda que alguns deles fossem gifs e não fossem facilmente indexado pelo script que utilizamos. Com essa base relativamente robusta, utilizamos a metodologia de análise de imagens do IBPAD a partir de uma versão adaptada do script memespector (André Mintz/Bernhard Rieder) que utiliza a Vision API do Google para fazer a leitura das imagens com inteligência artificial. A rede de imagens, produzida no Gephi, segue abaixo:
O agrupamento, como já expliquei em outro post, é feito através da correlação entre as imagens (estabelecida pelo processo de computação visual associado à aplicação de técnicas de análise de redes). Ou seja, de modo simples, imagens “semelhantes” – conforme identificadas pela inteligência artificial – ficam próximas umas das outras, resultando em agrupamentos específicos. Os 11 clusters identificados, desta vez, não foram delimitados pelo Gephi (como de costume), mas por nós mesmos. Uma breve descrição de cada um, de cima para baixo:
Comidas: aqui, há todo o tipo de comida comum ao brasileiro – desde os famosos “PFs” até alimentos específicos, como coxinha, brigadeiro, pastel com caldo de cana, e comidas mais regionais, como açaí, cuscuz e tacacá, além de algumas bebidas (como caipirinha, corote, etc.);
Casa & Lar: este agrupamento é composto por peças, móveis, aparelhos e decorações em geral comuns às casas brasileiras, como tipos específicos de filtro d’água, jogos de café e bordados decorativos, além de mesas de bar;
Jeitinho Brasileiro: este foi talvez o grupo mais difícil de identificar/classificar, pois apresenta imagens que não explicitamente significam algo em comum além do famoso jeitinho brasileiro – ou seja, são gambiarras, puxadinhos, improvisações, etc.
Animais: embora tenha rotulado de maneira generalista, este grupo é formado principalmente por cachorros (doguinhos) – com destaque para pinchers e vira-latas (e o caramelo, que acabou indo pro outro cluster);
Natureza: aqui encontramos imagens num tom mais político/de denúncia, com fotografias de queimadas em florestas e animais mortos;
Política/Futebol: não por coincidência logo abaixo do cluster de Natureza, este agrupamento traz imagens de políticos e – provavelmente devido à associação verde e amarela – também de futebol;
Notícias/Cotidiano: assim como Jeitinho Brasileiro, este também foi um agrupamento bem difícil de ser identificado, mas que chegamos ao consenso de que se trata de imagens de notícias/acontecimentos e cotidiano geral da realidade brasileira conforme narrada midiaticamente;
Textos: este agrupamento é formado principalmente por imagens com textos (como prints), o que dificulta sua compreensão, mas direciona se relaciona com Notícias/Cotidiano e abre alas para o cluster seguinte;
Memes: este é possivelmente o cluster mais diverso/confuso de toda a rede, no entanto, assim como o Jeitinho Brasileiro e Notícias/Cotidiano, temos aqui um exemplo de o quão a inteligência artificial pode ser eficaz para esse tipo de análise, visto que esse agrupamento corresponde às atribuições específicas de “internet meme” – onde temos Gretchen, Inês Brasil, Faustão e Selena Gomez, etc.;
Música: outro exemplo de eficácia da IA, visto que agrupou as imagens não pela sua composição de objetos (pessoas, por exemplo), mas pela sua classificação mais geral – são capas de álbuns de música ou outras associações a cantores/bandas;
TV/Cinema: o mesmo acontece neste grupo, com imagens de produções audiovisuais como filmes (Bacurau, O Auto da Compadecida, Minha Mãe É Uma Peça), novelas (Avenida Brasil, Vale Tudo) e programas em geral (Caldeirão do Huck, A Grande Família, Malhação).
Vale muito a pena fazer o download de imagem completa para navegar por toda a rede com mais minúcia e descobrir (se divertir também, mas cuidado para não travar o computador pois são 25mb de arquivo) com a criatividade dos usuários do Twitter. Além do mais, por mais que esses agrupamentos sirvam de análise geral do que compôs esse movimento, a curiosidade de cada imagem é ainda mais rica e vale por si só todo um debate – aqui, se uma imagem vale mais que mil palavras, temos 6 milhões de palavras para discutir.
E é com esse gancho que pretendemos, eu e Carol, produzir alguns artigos sobre essa análise. Além de essa discussão geral com os próprios resultados apresentados aqui (com mais detalhes e todo aprofundamento teórico-conceitual exigido pela academia), há algumas discussões já pensadas e possíveis para adiante: como será que usuários de diferentes regiões publicaram sobre o “seu” Brasil? Levando em consideração engajamento, quais temáticas prevaleceram? Quais são os benefícios e limitações da computação visual nesse processo? Fica aberta toda a discussão.
Na semana retrasada, enquanto navegava pelo Facebook, encontrei uma publicação da página Nordestinos que, em comemoração ao Dia do Nordestino (8 de outubro), questionava aos seus seguidores: pra você, o que é ser nordestino? Achei bem interessante porque imediatamente lembrei que foi literalmente essa uma das perguntas do meu trabalho de conclusão de curso na graduação, com um quórum muito menor.
Na monografia, intitulada “O que faz ser nordestino no Facebook: escolhas da construção identitária nos sites de redes sociais”, selecionei 18 pessoas – duas de cada estado do Nordeste – para responder a um simples questionário, que basicamente perguntava (abertamente) o que era ser nordestino e por que se apresentar nordestino no Facebook. A partir das respostas, consegui discutir no trabalho algumas questões que dialogavam diretamente com a base teórica que desenvolvi, pensando a invenção do nordeste, identidade (cultural) na modernidade, etc.
Publicação da página Nordestinos no Dia do Nordestino (8 de outubro)
Quando vi a publicação com a exata mesma pergunta que fiz no meu trabalho, bateu a curiosidade: será que consigo encontrar semelhanças (ou diferenças) entre as 18 respostas que obtive e as algumas centenas de comentários que os seguidores deixaram na publicação da página? Vale ainda pontuar que, no desenho metodológico que tracei para selecionar os respondentes do TCC, a página Nordestinos (que fez a publicação) foi uma das mais relevantes para o critério de seleção, o que empiricamente aproxima ainda mais as duas ocasiões.
Diferentemente da monografia, entretanto, na qual analisei resposta por resposta (afinal, eram menos de 20), tive que recorrer a uma técnica analítica mais quanti-qualitativa para lidar com as centenas de comentários que a publicação recebeu. Utilizei, portanto, a análise de rede semântica, que me permite identificar no corpus de texto quais são os principais territórios discursivos que se formam. Feita a coleta dos comentários com um código em R para raspagem dos dados, criei o arquivo de co-ocorrência no Wordij e trabalhei no Gephi finalizando no seguinte resultado:
Antes de entrar na rede, retomo algumas das respostas ou alguns pontos que identifiquei na monografia sobre o que seria “ser nordestino”: 1) simplesmente ter nascido em estados do Nordeste; 2) associar (por osmose) valores simbólicos atrelados ao território; 3) reconhecê-lo como lugar da tradição e origem (como nos romances de 30); 4) vivenciar comidas típicas e festividades como São João; 5) reconhecer-se como povo forte/batalhador, apesar das adversidades e secas; 6) reconhecer-se como povo sofrido, mas sempre alegre/receptivo; 7) reconhecer-se como comunidade; 8) ter orgulho de onde é/veio, sempre defendendo o seu local.
Informante 15, de Sergipe: “É ter o sotaque mais bonito, ter orgulho do seu povo e suas histórias, amar o mar mesmo no inverno. É poder compartilhar a nossa rica culinária e cultura com outras regiões, espalhar as nossas gírias que só quem é nordestino entende, é tratar qualquer pessoa de outra região com o mesmo respeito e alegria.”
(MEIRELLES, 2017, p. 71)
Não é preciso ir muito afundo na análise para perceber, de imediato, como as respostas de ambas estão praticamente em perfeita consonância. A diferença que consigo perceber é somente analítica, visto que a rede permite também que trabalhemos com proporção: os agrupamentos (clusters) encontrados partem do ponto de maior frequência, ou seja, os nós maiores – orgulho, cuscuz, feliz, povo – são fruto de uma maior assiduidade de respostas. No TCC, não trabalhei quantitativamente, apenas complexificando e organizando os pontos (já citados) que encontrei.
Importante ressaltar também como uma rede semântica, diferente de outras redes comuns à análise de/em mídias sociais (como perfis, páginas, canais, etc.), nem sempre é tão bem delimitada; muitas vezes, como neste caso específico, devido à similaridade discursiva do corpus, os clusters se embaralham e se entrelaçam em suas teias de significado. O Gephi encontrou, por exemplo, nove clusters, mas que eu transformaria em quatro – conforme listei na tabela comparativa abaixo. Lado a lado, é possível perceber as semelhanças entre os pontos.
TCC (18 respostas)
Facebook (+600 comentários)
Nascer no Nordeste
–
Valores simbólicos associados ao território
Sofre por problemas naturais, mas segue com fé e esperança (4)
Lugar da tradição e origem
Muito orgulho de sua história e identidade (1)
Comidas típicas e festividades
Desfruta das melhores comidas (2)
Povo forte/batalhador, apesar das adversidades e da seca
Povo guerreiro/batalhador, feliz apesar das dificuldades (3)
Povo sofrido, mas sempre alegre/receptivo
Sofre por problemas naturais, mas segue com fé e esperança (4)
Comunidade imaginada
Muito orgulho de sua história e identidade (1)
Orgulho da sua identidade
Muito orgulho de sua história e identidade (1)
Lembro como um dos feedbacks que recebi na banca foi a falta (ou a falha) de esquematização das minhas respostas – o que teria sido resolvido, por exemplo, com uma simples nuvem de palavras, a sugestão da professora. Por mais que eu compreenda essa necessidade científica de diminuir o social à fragmentação supostamente matemática do objeto, percebo também através dessa segunda tentativa o quão é difícil elencar esses valores. Talvez a mania de professor de colocar tudo em lista aqui não funcione tão bem.
Não porque não somos capazes de identificar quais são os valores associados ao que as pessoas compreendem no que seria “ser nordestino”, mas porque eles são e estão completamente embaralhados, tanto no discurso (semântico) quanto no imaginário. As coisas se sobrepõem, invadem o espaço uma das outras e vão de acordo ao que por tanto tempo se construiu como a narrativa do Nordeste e dos nordestinos. A comunidade inventada segue firme e forte, assumindo o lugar do oprimido que lhe foi imposto mas, talvez, pronto para se emancipar.
Obviamente, como discuti nas considerações finais do TCC, é de extrema importância complexificar tanto as respostas quanto o que está por trás das respostas (este que fiz nos dois primeiros capítulos, caso surja o interesse em saber). A primeira questão, entretanto, seguiria a discutir a generalização do todo em detrimento de alguns – de certo modo, como na construção do estereótipo: será que todas as pessoas que nasceram no Nordeste têm o sotaque arrastado, a cabeça chata, sofre(u) com a seca, etc.? Fica o questionamento para outro texto, quem sabe.
O texto “Um discurso sobre a ciências” (1987), de Boaventura de Sousa Santos, chegou até mim na primeira aula de Epistemologias que tive na pós. Refiro-me a ele como texto porque, ao lermos na própria sala de aula, ainda não tinha ciência de que aquele artigo de 22 páginas já havia sido publicado como livro com mais de 90 páginas em sua oitava edição pela Editora Cortez. Não suficiente, uma continuação com textos de vários autores compunham a coletânea “Conhecimento prudente para uma vida decente – ‘um discurso sobre as ciências’ revisitado”, de 2004.
Do mesmo modo que sua primeira publicação, feita em Portugal em 1987, causou um rebuliço intenso na comunidade acadêmica, também me impactou profundamente antes mesmo de descobrir todo esse contexto por trás da obra. Se, ao finalizar a leitura, já tinha como afirmativa de que ele precisava ser leitura básica em qualquer (ou melhor, em todas) disciplina(s) de graduação, depois que descobri toda a polêmica por trás de sua publicação (e continuações/revisões), não tenho dúvida de que ele deve ser apresentado e discutido sempre nas primeiras aulas. Sobre essas polêmicas, o autor explica no prefácio (da 8ª edição, que foi a que adquiri):
Em meados dos anos 1990, eclodiu, primeiro na Inglaterra e depois nos EUA, um novo episódio de debate aceso entre positivistas e antipositivistas, entre realistas e construtivistas, que em breve se transformou numa nova guerra da ciência. O momento mais intenso desta guerra ficou conhecido pelo nome de Sokal Affair, por ter tido origem num embuste redigido pelo físico matemático Alan Sokal e publicado na revista Social Text, com o objetivo de denunciar as supostas debilidades das posições antipositivistas ditas pós-modernas. Neste artigo, Sokal menciona, como textos representativos desta corrente, Um Discurso sobre as Ciências e Introdução a uma Ciência Pós-Moderna. Logo depois, o esclarecimento do embuste é publicado em Língua Franca (1996, 62/64), num artigo intitulado “A Physicist Experiments in Cultural Studies”. Em 1997, Sokal publica, junto com Jean Bricmont, o livro Impostures Intellectuelles, em que é desenvolvida a crítica aos filósofos e cientistas sociais “pós-modernos” franceses, genericamente acusados de uso incorrecto de teorias e conceitos das ciências físico-naturais. Entretanto, em 2002, foi publicado em Portugal um livro intitulado O Discurso Pós-moderno contra a Ciência: obscurantismo e irresponsabilidade, de autoria de António Manuel Baptista. Em grande medida, este livro repete, e nem sempre corretamente, os argumentos de Alan Sokal e dos que, do seu lado, intervieram nas guerras da ciência, tomando Um Discurso sobre as Ciências como o seu principal alvo. […]
(SOUSA DOS SANTOS, p.9-10)
Hoje, com 24 anos, formado e já no mestrado, consigo entender (e, metaforicamente, visualizar) tudo que engloba e atravessa esse trecho. Acho fundamental a sua leitura para absorver os argumentos que o autor levanta, mas – e talvez até mais enfaticamente – acho ainda mais relevante essa contextualização por trás da obra. A academia, em várias instâncias e de diferentes formas, sempre me ajudou/me ajuda a compreender melhor o mundo, e penso que o próprio caráter pedagógico-social do livro já reflete o que vemos para além de seus muros: é tudo disputa, é tudo luta – é tudo discurso (que envolve também performance) + relação de poder.
Parto dessa breve contextualização/explicação porque ela dialoga (ou introduz) também muito da própria proposta de conteúdo do texto: provocar as ordens de saber dominantes. Ainda que seja do final da década de 80, é extremamente atual pela aderência do debate com a força que ganhou nos últimos anos os estudos decoloniais/pós-coloniais/anti-coloniais (o próprio Boaventura é um dos organizadores da obra Epistemologias do Sul, possivelmente a mais popular sobre o tema no Brasil) e pela discussão explicitamente política que envolve fake news, pós-verdade, etc. – no geral, o intenso debate sobre como combater o anticientificismo e suas derivações.
Sem mais delongas, apresento a seguir um resumo comentado (como já é de costume aqui no blog) da obra, que está dividida em três grandes partes: (I) O paradigma dominante, na qual Boaventura situa como a ciência e o método científico se estabeleceu como modo de ver/crer/saber regente; (II) A crise do paradigma dominante, quando aponta os problemas que desencadearam da lógica mecanicista da ciência moderna e; (III) O paradigma emergente, onde enuncia alguns dos pressupostos fundamentais para a concepção do que veio a se convencionar (e se criticar) de ciência pós-moderna (todo conhecimento é social, local/total, autoconhecimento e visa o senso comum).
Antes de entrar no texto, vale explicar (para quem não conhece) algumas das terminologias frequentemente utilizadas pelo autor: epistemologia (e suas derivações, como “condições epistêmicas”) é, basicamente, uma ordem de conhecimento – ou seja, é o modo de “fazer crer”, como, por exemplo, o método científico; positivismo (e, novamente, suas derivações, como antipositivismo, linha de argumento a qual o autor se alinha) é uma corrente de pensamento ancorada nos ideais de Auguste Comte, na qual a razão é produto indissociável do progresso – ou seja, só a iluminação do conhecimento (científico) seria capaz de levar uma sociedade para frente.
E é nesse tom que Boaventura inicia o texto: estamos (já há algumas décadas) num período de transição ambíguo e complexo “descompassado em relação a tudo o que o habita”. Ele inicia seu argumento afirmando que “perdemos a confiança epistemológica”, o que tem causado uma “sensação de perda” tanto pela perda em si quanto por não sabermos ao certo o que estamos perdendo. No entanto, o mesmo sentimento que assusta é também o que entusiasma: para surgir o novo, precisamos encarar e deixar para trás a estabilidade que nos ancorou por tanto tempo no velho.
Estamos no fim de um ciclo de hegemonia de uma certa ordem científica. As condições epistémicas das nossas perguntas estão inseridas no avesso dos conceitos quo utilizamos para lhes dar resposta. É necessário um esforço de desvendamento conduzido sobre um fio de navalha entre a lucidez e a ininteligibilidade da resposta. São igualmente diferentes e muito mais complexas as condições sociológicas e psicológicas do nosso perguntar. É muito diferente perguntar pela utilidade ou pela felicidade que o automóvel me pode proporcionar se a pergunta é feita quando ninguém na minha vizinhança tem automóvel, quando toda a gente tem excepto eu ou quando eu próprio tenho carro há mais do vinte anos.
(SOUSA SANTOS, p.17-18)
O paradigma dominante
Na primeira seção, o autor caracteriza brevemente a ordem científica hegemônica, com uma preocupação latente em contextualizar social e historicamente seu surgimento e viradas epistêmicas. Explica, por exemplo, que esse paradigma é fruto da revolução científica do século XVI, baseado nos estudos das ciências naturais e que só chega – ou melhor, impõem-se – sobre as ciências sociais no século XIX. Essa racionalidade científica seria um modelo global e totalitário, “na medida em que nega o carácter racional a todas as formas de conhecimento que se não pautarem pelos seus princípios epistemológicos e pelas suas regras metodológicas”.
O que Boaventura se propõe a explicar aqui é como o conhecimento científico se consagrou com parâmetros e propostas rigorosas que se diferenciam dos outros tipos de conhecimento hegemônicos anteriores, como a teologia e a metafísica. Essa característica, que soaria como universal – no sentido que seria válida para todos, um “ponto zero comum” -, deu aos protagonistas dessa revolução toda a confiança necessária para legitimar esse novo modo de saber. Para além da simples observação dos fatos, a ciência moderna se distinguiu do saber aristotélico e medieval ao estabelecer uma nova visão do mundo e da vida que “desconfia sistematicamente das evidência da nossa experiência imediata”.
As ideias que presidem à observação e à experimentação são as ideias claras e simples a partir das quais se pode ascender a um conhecimento mais profundo e rigoroso da natureza. Essas ideias são as ideias matemáticas. A matemática fornece à ciência moderna, não só o instrumento privilegiado de análise, como também a lógica da investigação, como ainda o modelo de representação da própria estrutura da matéria. […] Deste lugar central da matemática na ciência moderna derivam duas consequências principais. Em primeiro lugar, conhecer significa quantificar. O rigor científico afere-se pelo rigor das medições. As qualidades intrínsecas do objecto são, por assim dizer, desqualificadas e em seu lugar passam a imperar as quantidades em que eventualmente se podem traduzir. O que não é quantificável é cientificamente irrelevante. Em segundo lugar, o método científico assenta na redução da complexidade. O mundo é complicado e a mente humana não o pode compreender completamente. Conhecer significa dividir e classificar para depois poder determinar relações sistemáticas entre o que se separou. […] Esta distinção entre condições iniciais e leis da natureza nada tem de “natural”. Como bem observa Eugene Wigner, é mesmo completamente arbitrária. No entanto, é nela que assenta toda a ciência moderna.
(SOUSA SANTOS, p. 26-29)
Em outras palavras, o autor está dizendo que a ciência estabeleceu um protocolo de atuação que visa a formulação de leis a partir de regularidades observadas a fim de prever o futuro. Neste contexto, explica os quatros tipos de causa (essência da ciência moderna) para Aristóteles: a material, a formal, a eficiente e a final. “As leis da ciência moderna são um tipo de causa formal que privilegia o como funciona das coisas em detrimento de qual o agente ou qual o fim das coisas”, pontua. Ou seja, o propósito fundamental da ciência moderna é o de reprodutibilidade: compreender como acontece/aconteceu no presente/passado para que seja possível repetir no futuro.
A ideia de ordem e estabilidade do mundo é o pressuposto principal para esse projeto epistêmico, que também se traduz como pré-condição para a transformação tecnológica do real. Boaventura cita, aqui, a noção de mundo-máquina de Newton, no qual “o mundo da matéria é uma máquina cujas operações se podem determinar exactamente por meio de leis físicas e matemáticas, um mundo estático e eterno a flutuar num espaço vazio”, ou ainda, “um mundo que o racionalismo cartesiano torna cognoscível por via da sua decomposição nos elementos que o constituem”. E é essa ideia que se constitui como hipótese universal da época, averiguada como mecanicismo.
Esse determinismo mecanicista, conforme explica, é essencialmente utilitário e funcional, mais preocupado em dominar e transformar do que em “compreender profundamente o real”. Sendo filho das ciências naturais, foi assumido pelas ciências sociais sob duas vertentes: a primeira, “dominante, consistiu em aplicar, na medida do possível, ao estudo da sociedade todos os princípios epistemológicos e metodológicos que presidiam ao estudo da natureza desde o século XVI”; enquanto a segunda “consistiu em reivindicar para as ciências sociais um estatuto epistemológico e metodológico próprio, com base na especificidade do ser humano e sua distinção polar em relação à natureza”.
A primeira variante/vertente
Ciências naturais = modelo de conhecimento universalmente (e único) válido;
Fenômenos naturais e sociais podem ser estudados da mesma maneira;
Visão durkheimiana: “é necessário reduzir os factos sociais às suas dimensões externas, observáveis e mensuráveis”;
OBSTÁCULO I: “as ciências sociais não dispõem de teorias explicativas que lhes permitam abstrair do real para depois buscar nele, de modo metodologicamente controlado, a prova adequada”;
OBSTÁCULO II: “as ciências sociais não podem estabelecer leis universais porque os fenómenos sociais são historicamente condicionados e culturalmente determinados”;
OBSTÁCULO III: “as ciências sociais não podem produzir previsões fiáveis porque os seres humanos modificam o seu comportamento em função do conhecimento que sobre ele se adquire”;
OBSTÁCULO IV: “os fenómenos sociais são de natureza subjectiva e como tal não se deixam captar pela objectividade do comportamento”;
OBSTÁCULO V: “as ciências sociais não são objectivas porque o cientista social não pode libertar-se, no acto de observação, dos valores que informam a sua prática em geral e, portanto, também a sua prática de cientista”.
A segunda variante/vertente
Reivindica para as ciências sociais um estatuto metodológico próprio;
O argumento fundamental é que a ação humana é radicalmente subjectiva;
Ciências social é subjetiva -> “tem de compreender os fenómenos sociais a partir das atitudes mentais e do sentido que os agentes conferem às suas acções”
São necessários métodos de investigação e critérios epistemológicos diferentes das ciências naturais;
PROBLEMA – “Partilha com este modelo a distinção natureza/ser humano e tal como ele tem da natureza uma visão mecanicista a qual contrapõe, com evidência esperada, a especificidade do ser humano”.
Talvez o mais interessante, a meu ver, deste capítulo, é refletirmos como esse modo de fazer crer – ou seja, a epistemologia do conhecimento científico – é o alicerce de várias instâncias da vida em sociedade hoje. Se pensarmos em todo o molde de currículo estrutural escolar, por exemplo, temos uma aplicação bastante evidente de como isso pode ser traduzido. A própria ordem de disciplinas, separadas em diferentes áreas de conhecimento, são fruto dessa lógica de dividir para (re)produzir – e assim criam-se operadores da máquina capitalista.
A crise do paradigma dominante
Na segunda seção, o autor argumenta pelos sinais de crise do modelo de racionalidade científica a partir de três questões principais: 1) trata-se de uma crise profunda e irreversível; 2) o período de revolução científica dura desde Einstein até a atualidade, sem previsão de fim; 3) podemos apenas especular sobre o que virá a seguir como fruto desse período revolucionário, ainda que já seja possível “afirmar com segurança que colapsarão as distinções básicas em que assenta o paradigma dominante e a que aludi na secção precedente”.
A primeira condição teórica (que se une a uma pluralidade de outras, também sociais) resultante dessa crise é o avanço do próprio conhecimento científico, que “permitiu ver a fragilidade dos pilares em que se funda” – a exemplo da relatividade da simultaneidade de Einstein. A segunda condição teórica, segundo o autor, é o surgimento da mecânica quântica – que relativizou a microfísica como Einstein o fez com as leis de Newton. Nesse contexto, surgem três problemáticas: uma vez que o rigor científico é estruturalmente limitado, as leis da física seriam “tão-só probabilísticas”; a totalidade do real é incabível de redução à soma das partes para observação e mensuração; sujeito e objeto não são tão afastados assim.
O teorema da incompletude (ou do não completamento) e os teoremas sobre a impossibilidade, em certas circunstâncias, de encontrar dentro de um dado sistema formal a prova da sua consistência vieram mostrar que, mesmo seguindo à risca as regras da lógica matemática, é possível formular proposições indecidíveis, proposições que se não podem demonstrar nem refutar, sendo que uma dessas proposições é precisamente a que postula o carácter não-contraditório do sistema. Se as leis da natureza fundamentam o seu rigor no rigor das formalizações matemáticas em que se expressam, as investigações de Gödel vêm demonstrar que o rigor da matemática carece ele próprio de fundamento. A partir daqui é possível não só questionar o rigor da matemática como também redefini-lo enquanto forma de rigor que se opõe a outras formas de rigor alternativo, uma forma de rigor cujas condições de êxito na ciência moderna não podem continuar a ser concebidas como naturais e óbvias.
(SOUSA SANTOS, p. 47-48)
Há em voga um movimento convergente que, junto as já referenciadas condições teóricas da crise, tem propiciado “uma profunda reflexão epistemológica sobre o conhecimento científico”. Compõem-na duas facetas sociológicas, segundo o autor: é capitaneada “por cientistas que adquiriram uma competência e um interesse filosófico para problematizar a sua prática científica”; e abrange questões antes relegadas apenas a sociólogos – e agora centrais ao novo modelo -, como “a análise das condições sociais, dos contextos culturais, dos modelos organizacionais da investigação científica”.
Alguns dos temas principais dessa reflexão epistemológica são:
O conceito de lei e de causalidade associado são questionados;
O rigor científico é questionado no seu caráter epistemológico totalitário;
A irredutibilidade dos objetos é enfrentada em seus diversos limites e problemáticas.
Boaventura fecha esta seção falando sobre a problemática da industrialização da ciência: “referirei tão-só que, quaisquer que sejam os limites estruturais de rigor científico, não restam dúvidas que o que a ciência ganhou em rigor nos últimos quarenta ou cinquenta anos perdeu em capacidade de auto-regulação”. Ratifica que “as ideias da autonomia da ciência e do desinteresse do conhecimento científico, que durante muito tempo constituíram a ideologia espontânea dos cientistas, colapsaram perante o fenómeno global da industrialização da ciência a partir sobretudo das décadas de trinta e quarenta”.
“A ciência e a tecnologia têm vindo a revelar-se as duas faces de um processo histórico em que os interesses militares e os interesses económicos vão convergindo até quase a indistinção”
Boaventura de Sousa Santos
O final desta seção é bem interessante porque, ao mesmo tempo em que coloca o dedo na ferida e basicamente diz: foi a ciência (ou pelo menos legitimados pela ciência) que nos levou às guerras, à exploração, à opressão, à escravidão, etc.; ainda mantém o entusiasmo ao afirmar que a crise é “o retrato de uma família […] criativa e fascinante, no momento de se despedir […] dos lugares conceituais, teóricos e epistemológicos, ancestrais e íntimos, mas não mais convincentes e securizantes” – e acrescenta: “uma despedida em busca de uma vida melhor a caminho doutras paragens onde o optimismo seja mais fundado e a racionalidade mais plural e onde finalmente o conhecimento volte a ser uma aventura encantada”.
Aqui, retomo o que falei no início do post sobre o caráter para além do conteúdo do texto que, a meu ver, é também instrumento pedagógico fundamental em sala de aula: o autor está jogando o jogo da disputa. Depois de passar uma seção (ou capítulo) inteira(o) citando problemas que as próprias ciências naturais acabaram encontrando conforme seus próprios paradigmas, amacia a mensagem basicamente falando que cientistas podem ser bonzinhos, só estão perdidos (parafraseando Criolo). Ou ele está tentando agradar um público que também quer persuadir com o texto, ou está simplesmente usufruindo do privilégio da epistemologia da ignorância.
O paradigma emergente
Na última seção, Boaventura apresenta o paradigma emergente a partir de quatro teses principais: 1) todo o conhecimento é científico-social; 2) é local e total; 3) é auto-conhecimento; 4) e visa constituir-se em senso comum. Antes, ratifica que são premissas para o futuro que “o que dele dissermos é sempre o produto de uma síntese pessoal embebida na imaginação, no meu caso na imaginação sociológica”. Ainda mais importante, também chama a atenção para o caráter desta revolução: “sendo uma revolução científica que ocorre numa sociedade ela própria revolucionada pela ciência, o paradigma a emergir dela não pode ser apenas um paradigma científico […], tem de ser também um paradigma social […]”.
1. Todo o conhecimento científico-natural é científico-social
A primeira tese do autor argumenta pelo fim da distinção dicotômica entre ciências naturais e ciências sociais e elege esta como catalisador necessário do paradigma emergente. Num primeiro momento, ele então discorre sobre diversas teorias da ciência moderna que “introduzem na matéria os conceitos de historicidade e de processo, de liberdade, de auto-determinação e até de consciência que antes o homem e a mulher tinham reservado para si”. Além desse esforço, ainda explica a importância da mecânica quântica como responsável pela transformação na distinção atual entre sujeito e objeto.
O conhecimento do paradigma emergente tende assim a ser um conhecimento não dualista, um conhecimento que se funda na superação das distinções tão familiares e óbvias que até há pouco considerávamos insubstituíveis, tais como natureza/cultura, natural/artificial, vivo/inanimado, mente/matéria, observador/observado, subjectivo/objectivo, colectivo/individual, animal/pessoa. Este relativo colapso das distinções dicotómicas repercute-se nas disciplinas científicas que sobre elas se fundaram.
(SOUSA SANTOS, p. 69)
Para além da superação dessa distinção, Boaventura argumenta também que é necessário enunciar “quem” dita o caminho a seguir. “Precisamente porque vivemos um estado de turbulência, as vibrações do novo paradigma repercutem-se desigualmente nas várias regiões do paradigma vigente e por isso os sinais do futuro são ambíguos”, explica. É nesse contexto que surgem matérias como a sociobiologia, cuja superação da dicotomia alinha muito mais a favor das ciências naturais. No entanto, se “atentarmos no conteúdo teórico das ciências que mais têm progredido no conhecimento da matéria, verificamos que a emergente inteligibilidade da natureza é presidida por conceitos, teorias, metáforas e analogias das ciências sociais”.
A máxima dukrheimiana seria, portanto, invertida: os fenômenos naturais deveriam ser estudados como fenômenos sociais (e não o contrário). Ainda assim, argumenta o autor, superar essa dicotomia pela égide das ciências sociais ainda não é um movimento “suficiente para caracterizar o modelo de conhecimento no paradigma emergente”. Como já explicou previamente, isso porque “as próprias ciências sociais constituíram-se no século XIX segundo os modelos de racionalidade das ciências naturais clássicas”. Como solução para essa armadilha, que pode ser apenas ilusória, Boaventura sugere um caminho direcionado ao campo de saber das humanidades, cujo projeto epistêmico é ainda mais subjetivo e relativo.
A superação da dicotomia ciências naturais/ciências sociais tende assim a revalorizar os estudos humanísticos. Mas esta revalorização não ocorrerá sem que as humanidades sejam, elas também, profundamente transformadas. O que há nelas de futuro é o terem resistido à separação sujeito/objecto e o terem preferido a compreensão do mundo à manipulação do mundo. Este núcleo genuíno foi, no entanto, envolvido num anel de preocupações mistificatórias (o esoterismo nefelibata e a erudição balofa). O ghetto a que as humanidades se remeteram foi em parte uma estratégia defensiva contra o assédio das ciências sociais, armadas do viés cientista triunfalmente brandido. Mas foi também o produto do esvaziamento que sofreram em face da ocupação do seu espaço pelo modelo cientista. […] Há que recuperar esse núcleo genuíno e pô-lo ao serviço de uma reflexão global sobre o mundo.
(SOUSA SANTOS, p. 76)
Confesso que o termo “humanidades”, para mim, não é tão comum. Apenas recordo de tê-lo visto em artigos/produções acadêmicas (geralmente em inglês) relacionados às chamadas “humanidades digitais” – mas que nunca me foi explicado ou que busquei compreender em sua complexidade, tomando-a como em sua concepção minimamente literal. “É pois necessário descobrir categorias de inteligibilidade globais, conceitos quentes que derretam as fronteiras em que a ciência moderna dividiu e encerrou a realidade”, pontua. “A ciência pós-moderna é uma ciência assumidamente analógica que conhece o que conhece pior através do que conhece melhor”.
O autor encerra esta primeira tese com um argumento que dialoga bastante com a minha trajetória acadêmica deste ano, conforme a urgência que notei – e adotei – de mudança de projeto do mestrado. É talvez a primeira vez que ele coloca, de maneira escancarada, o sujeito-pesquisador enquanto potência. Essa é uma das críticas que tenho ao texto, a qual já tinha pontuado brevemente ao final da primeira seção e que se repete de modo ainda mais grave (a meu ver) em parte da próxima tese, a seguir. No entanto, aqui, confesso que fui bastante atravessado ao modo como encerra:
Já mencionei a analogia textual e julgo que tanto a analogia lúdica como a analogia dramática, como ainda a analogia biográfica, figurarão entre as categorias matriciais do paradigma emergente: o mundo, que hoje é natural ou social e amanhã será ambos, visto como um texto, como um jogo, como um palco ou ainda como uma autobiografia. […] A nudez total, que será sempre a de quem se vê no que vê, resultará das configurações de analogias que soubermos imaginar: afinal, o jogo pressupõe um palco, o palco exercita-se com um texto e o texto é a autobiografia do seu autor. Jogo, palco, texto ou biografia, o mundo é comunicação e por isso a lógica existencial da ciência pós-moderna é promover a “situação comunicativa” tal como Habermas a concebe. Nessa situação confluem sentidos e constelações de sentido vindos, tal qual rios, das nascentes das nossas práticas locais e arrastando consigo as areias dos nossos percursos moleculares, individuais, comunitários, sociais e planetários.
(SOUSA SANTOS, 77-79)
2. Todo o conhecimento é local e total
Para argumentar por sua segunda tese, Boaventura critica a hiper-especialização da ciência moderna: “a excessiva parcelização e disciplinarização do saber científico faz do cientista um ignorante especializado”. Explica que o avanço pela especialização acarretou no dilema básico da ciência moderna: “o seu rigor aumenta na proporção directa da arbitrariedade com que espartilha o real”. Ainda que os males desse fenômeno já sejam reconhecidos, a ainda mantida disciplinarização (que organiza o saber e policia as fronteiras contra transposição) de novas disciplinas reproduzem o mesmo modelo de cientificidade.
Contra a parcelização do conhecimento, o autor defende o conhecimento total (universal e/ou indivisível) do paradigma emergente. Em vez de disciplinas, sugere temas, “galerias por onde os conhecimentos progridem ao encontro uns dos outros”. Contrário ao paradigma dominante, o novo paradigma tem o avanço do conhecimento “à medida que o seu objecto se amplia, ampliação que, como a da árvore, procede pela diferenciação e pelo alastramento das raízes em busca de novas e mais variadas interfaces”. Em outras palavras, é um passo em direção ao caráter interdisciplinar da academia – não de novas disciplinas, mas disciplinas dialogando entre si.
A segunda parte do argumento por esse conhecimento local é a que mais me incomodou em todo o texto: “o conhecimento pós-moderno é também total porque reconstitui os projectos cognitivos locais, salientando-lhes a sua exemplaridade, e por essa via transforma-os em pensamento total ilustrado”. Ainda sobre a ciência do paradigma emergente, acrescenta: “sendo […] assumidamente analógica, é também assumidamente tradutora, ou seja, incentiva os conceitos e as teorias desenvolvidos localmente a emigrarem para outros lugares cognitivos, de modo a poderem ser utilizados fora do seu contexto de origem”.
Eu não sei se entendi errado, ou se de fato ele quis dizer que o conhecimento pós-moderno pode transpor um conhecimento específico para outra realidade completamente diferente. Não é isso que a ciência moderna já faz? Em outro trecho, ele até reconhece isso, mas passando pano para o paradigma emergente: “Este procedimento [de tradução], que é reprimido por uma forma de conhecimento que concebe através da operacionalização e generaliza através da quantidade e da uniformização, será normal numa forma de conhecimento que concebe através da imaginação e generaliza através da qualidade e da exemplaridade”.
Novamente, não sei se entendi errado, mas, caso esteja correto, o que o autor faz é simplesmente privilégio acadêmico. Mais uma vez, ignora – ou melhor, vangloria – o sujeito-pesquisador, colocando-o o cientista pós-moderno tão iluminado quanto o cientista moderno que tanto critica. É conivente com as relações de poder que estão em jogo também na academia, que, como ele mesmo já afirmou anteriormente, traduz-se para toda a sociedade (visto que é onde parte a revolução científica da sociedade científica). E aí, enfim, esquece quem, histórica e socialmente, sempre teve a possibilidade de habitar esse espaço e criar/legitimar suas epistemologias.
O conhecimento pós-moderno, sendo total, não é determinístico, sendo local, não é descritivista. É um conhecimento sobre as condições de possibilidade. As condições de possibilidade da acção humana projectada no mundo a partir de um espaço-tempo local. Um conhecimento deste tipo é relativamente imetódico, constitui-se a partir de uma pluralidade metodológica. Cada método é uma linguagem e a realidade responde na língua em que é perguntada. Só uma constelação de métodos pode captar o silêncio que persiste entre cada língua que pergunta. Numa fase de revolução científica como a que atravessamos, essa pluralidade de métodos só é possível mediante transgressão metodológica. Sendo certo que cada método só esclarece o que lhe convém e quando esclarece fá-lo sem surpresas de maior, a inovação científica consiste em inventar contextos persuasivos que conduzam à aplicação dos métodos fora do seu habitat natural.
(SOUSA SANTOS, p. 83-84)
Mais uma vez, entretanto, o autor finaliza a tese de modo muito interessante, agora colocando o sujeito-pesquisador como potência criativa (entusiasta), porém possivelmente transgressora. Cabe a este ator transgredir metodologicamente para desenvolver um estilo literário novo, “uma configuração de estilos construída segundo o critério e a imaginação pessoal do cientista”. Em contraponto à suposta imparcialidade do racional científico moderno, aposta na “composição transdisciplinar e individualizada [… que] sugere um movimento no sentido da maior personalização do trabalho científico”.
3. Todo o conhecimento é auto-conhecimento
A terceira tese é, para mim, a mais interessante. Se critiquei o autor algumas vezes até aqui por conscientemente esquivar o sujeito do debate, é aqui que ele se redime de todas as minhas críticas. Boaventura começa este argumento explicando a problemática distinção dicotômica entre sujeito e objeto: “um conhecimento objectivo, factual e rigoroso não tolerava a interferência dos valores humanos ou religiosos”. Reconhece, entretanto, que essa distinção nunca foi tão simples nas ciências sociais, afinal éramos nós estudando nós mesmos. Parte daí a diferenciação básica entre sociologia e antropologia, que inicialmente se afastaram e a tendência agora é convergirem metodologicamente cada vez mais.
Parafraseando Clausewitz, podemos afirmar hoje que o objecto é a continuação do sujeito por outros meios. Por isso, todo o conhecimento científico é auto-conhecimento. A ciência não descobre, cria, e o acto criativo protagonizado por cada cientista e pela comunidade científica no seu conjunto tem de se conhecer intimamente antes que conheça o que com ele se conhece do real. Os pressupostos metafísicos, os sistemas de crenças, os juízos de valor não estão antes nem depois da explicação científica da natureza ou da sociedade. São parte integrante dessa mesma explicação. A ciência moderna não é a única explicação possível da realidade e não há sequer qualquer razão científica para a considerar melhor que as explicações alternativas da metafísica, da astrologia, da religião, da arte ou da poesia. A razão por que privilegiamos hoje uma forma de conhecimento assente na previsão e no controlo dos fenómenos nada tem de científico. É um juízo de valor. A explicação científica dos fenómenos é a auto-justificação da ciência enquanto fenómeno central da nossa contemporaneidade. A ciência é, assim, autobiográfica.
(SOUSA SANTOS, 89-90)
O que ele chama atenção aqui é justamente sobre como o fazer científico é atravessado pelo intermediário que é o sujeito cientista, citando como exemplo o próprio Descartes, em Discurso do Método. “No início, os protagonistas da revolução científica tiveram a noção clara que a prova íntima das suas convicções pessoais precedia e dava coerência às provas externas que desenvolviam”, explica. É como se a ciência, em sua máxima de imparcialidade e rigor, tivesse esquecido do básico: o instrumento que nos faz entender o real somos nós mesmos, cheios de bagagens, interpretações e atravessamentos.
“Hoje sabemos ou suspeitamos que as nossas trajectórias de vida pessoais e colectivas (enquanto comunidades científicas) e os valores, as crenças e os prejuízos que transportam são a prova íntima do nosso conhecimento”, aponta. Sem isso, “as nossas investigações laboratoriais ou de arquivo, os nossos cálculos ou os nossos trabalhos de campo constituiriam um emaranhado de diligências absurdas sem fio nem pavio”. Boaventura argumenta que, entretanto: “este saber, suspeitado ou insuspeitado, corre hoje subterraneamente, clandestinamente, nos não-ditos dos nossos trabalhos científicos”.
No paradigma emergente, o carácter autobiográfico e auto-referenciável da ciência é plenamente assumido. A ciência moderna legou-nos um conhecimento funcional do mundo que alargou extraordinariamente as nossas perspectivas de sobrevivência. Hoje não se trata tanto de sobreviver como de saber viver. Para isso é necessária uma outra forma de conhecimento, um conhecimento compreensivo e íntimo que não nos separe e antes nos una pessoalmente ao que estudamos. A incerteza do conhecimento, que a ciência moderna sempre viu como limitação técnica destinada a sucessivas superações, transforma-se na chave do entendimento de um mundo que mais do que controlado tem de ser contemplado. Não se trata do espanto medieval perante uma realidade hostil possuída do sopro da divindade, mas antes da prudência perante um mundo que, apesar de domesticado, nos mostra cada dia a precaridade do sentido da nossa vida por mais segura que esteja ao nível da sobrevivência. A ciência do paradigma emergente é mais contemplativa do que activa. A qualidade do conhecimento afere-se menos pelo que ele controla ou faz funcionar no mundo exterior do que pela satisfação pessoal que dá a quem a ele acede e o partilha.
(SOUSA SANTOS, p.92-93)
E mais uma vez, termina, a meu ver, de forma brilhante: “a criação científica no paradigma emergente assume-se como próxima da criação literária ou artística, porque a semelhança destas pretende que a dimensão activa da transformação do real (o escultor a trabalhar a pedra) seja subordinada à contemplação do resultado (a obra de arte)”. E acrescenta: “a crítica literária anuncia a subversão da relação sujeito/objecto que o paradigma emergente pretende operar; […] o objecto do estudo, como se diria em termos científicos, sempre foi, de facto, um super-sujeito (um poeta, um romancista, um dramaturgo) face ao qual o crítico não passa de um sujeito ou autor secundário”.
4. Todo o conhecimento científico visa constituir-se em senso comum
Sua quarta e final tese critica o afastamento do conhecimento científico das outras formas de conhecimento ao mesmo tempo em que atribui à ciência pós-moderna a responsabilidade racional de fazer essa aproximação para que, então, torne-se também parte desse amaranhado. “A ciência moderna construiu-se contra o senso comum que considerou superficial, ilusório e falso. A ciência pós-moderna procura reabilitar o senso comum por reconhecer nesta forma de conhecimento algumas virtualidades para enriquecer a nossa relação com o mundo”, explica.
O senso comum faz coincidir causa e intenção; subjaz-lhe uma visão do mundo assente na acção e no princípio da criatividade e da responsabilidade individuais. O senso comum é prático e pragmático; reproduz-se colado às trajectórias e às experiências de vida de um dado grupo social e nessa correspondência se afirma fiável e securizante. O senso comum é transparente e evidente; desconfia da opacidade dos objectivos tecnológicos e do esoterismo do conhecimento em nome do princípio da igualdade do acesso ao discurso, à competência cognitiva e à competência linguística. O senso comum é superficial porque desdenha das estruturas que estão para além da consciência, mas, por isso mesmo, é exímio em captar a profundidade horizontal das relações conscientes entre pessoas e entre pessoas e coisas. O senso comum é indisciplinar e imetódico; não resulta de uma prática especificamente orientada para o produzir; reproduz-se espontaneamente no suceder quotidiano da vida. O senso comum aceita o que existe tal como existe; privilegia a acção que não produza rupturas significativas no real. Por último, o senso comum é retórico e metafísico; não ensina, persuade.
(SOUSA SANTOS, 96-97)
Esse com certeza é o argumento mais polêmico do autor. É extremamente complicado em diversas instâncias, principalmente na onde bastante atual de anticientificismo (terraplanismo, antivacina, etc.). Eu entendo, entretanto, onde o autor esteja querendo chegar aqui: ele quer prezar pela “dimensão utópica e libertadora” do senso comum que “pode ser ampliada através do diálogo com o conhecimento científico”. Isso não quer dizer descartar por completo o conhecimento científico nem colocar o senso comum como estatuto de verdade, mas simplesmente abrir a estrutura enclausurante do primeiro para com o segundo.
“Deixado a si mesmo, o senso comum é conservador e pode legitimar prepotências, mas interpenetrado pelo conhecimento científico pode estar na origem de uma nova racionalidade”, explica. Há, para o autor, que se inverter a ruptura epistemológica: do conhecimento científico para o senso comum – tanto o primeiro bebendo da fonte do último quanto o primeiro eventualmente tornando-se também o último. Novamente, entendo como isso é radical – no sentido de ir à raiz mesmo – e, portanto, complicado de ser recebido sem resistência – e muito provavelmente daí surjam todas as críticas que o procederam.
A ciência pós-moderna, ao sensocomunizar-se, não despreza o conhecimento que produz tecnologia, mas entende que, tal como o conhecimento se deve traduzir em auto-conhecimento, o desenvolvimento tecnológico deve traduzir-se em sabedoria de vida. É esta que assinala os marcos da prudência à nossa aventura científica. A prudência é a insegurança assumida e controlada.
(SOUSA SANTOS, p. 98)
Talvez o maior problema do texto, que é o que possivelmente acarreta nas críticas que citei, seja não localizar explicitamente o conhecimento científico enquanto estatuto legitimado de relação de poder. E aí o contexto, mais uma vez no jogo que cito desde o início, importa: Boaventura é português, formado em Direito, homem, branco, etc. Ou ele não precisa passar por esse enfrentamento ou ele simplesmente não quer, para conseguir agradar parte de sua audiência. Ainda assim, não tenho dúvidas de quanto é e foi um texto necessário (complicado, mas necessário).
“Nenhum de nós pode neste momento visualizar projectos concretos de investigação que correspondam inteiramente ao paradigma emergente que aqui delineei”, reconhece, por estarmos (na década de 80) numa fase de transição. “Duvidamos suficientemente do passado para imaginarmos o futuro, mas vivemos demasiadamente o presente para podermos realizar nele o futuro. Estamos divididos, fragmentados. Sabemo-nos a caminho mas não exactamente onde estamos na jornada. A condição epistemológica da ciência repercute-se na condição existencial dos cientistas”, finaliza. E é aí que entra a importância da academia está mudando de cara e de cor.
SANTOS SOUSA, Boaventura. Um discurso sobre as ciências. 8ª edição. São Paulo, Cortez: 2018.